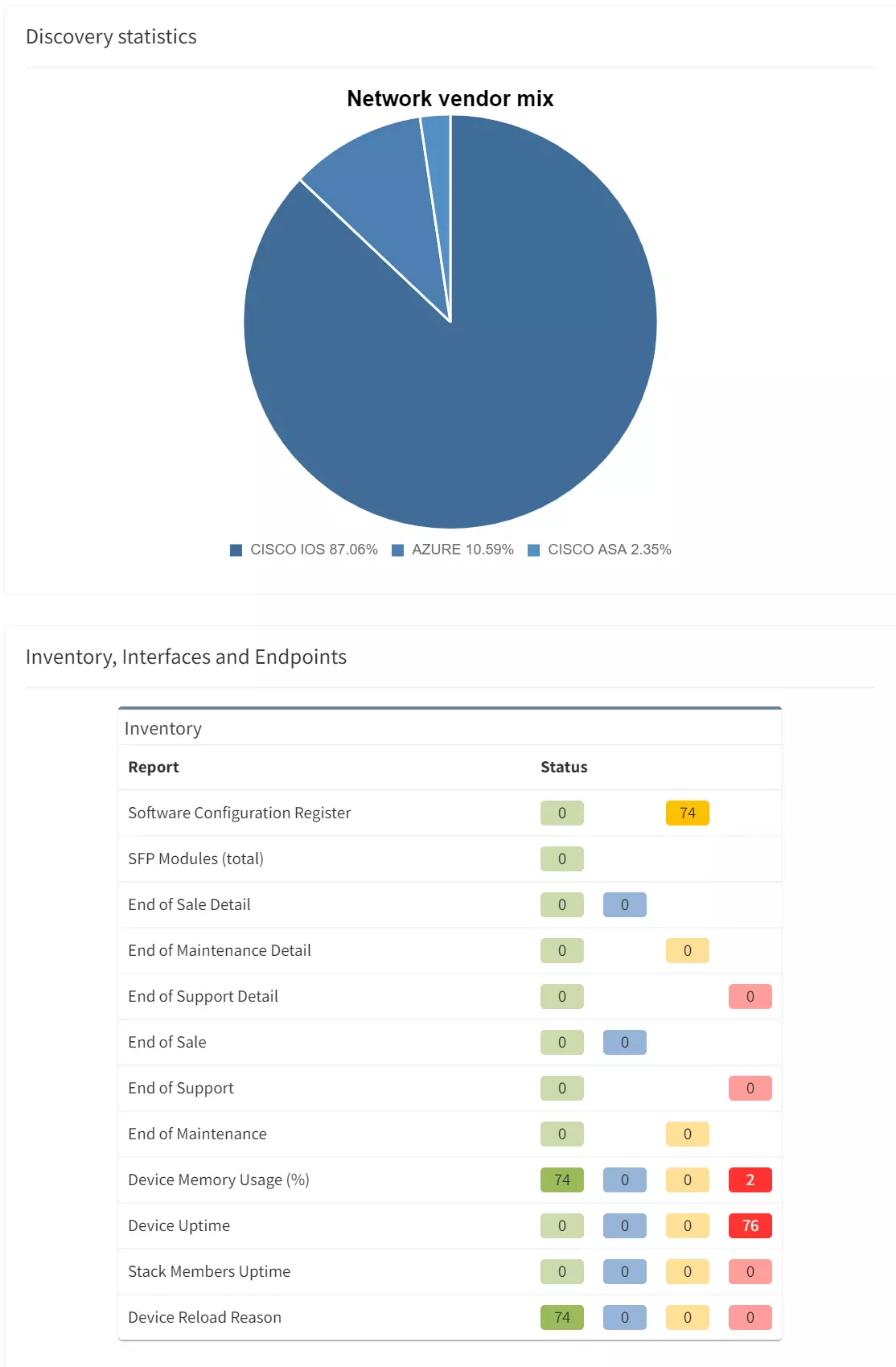
Enterprise networks should never have Single Points of Failure (a.k.a SPOF) in their daily operation. SPOF in general is an element in a system which, if stopped, causes the whole system to stop.
Single failure (or maintenance or misconfiguration) of any network device or link should never put a network down and require manual intervention. Network architects know this rule and design the networks like that — placing redundant/backup devices and links which can take over all functions if the primary device/link fails.
But the reality is not always pleasant, and today’s operational networks can include SPOFs without anyone explicitly knowing. The reason is that even though the original design put all SPOFs away, the network may have evolved in the meantime, and new infrastructure may have been connected to it.
For example:
Part of the network operation activities should take into account that SPOFs may appear unexpectedly. This require advanced skills and lot of time to go trough routine settings and outputs if the networks is still resilient and high available. It also requires expensive disaster-recovery exercises to be performed regularly.
IP Fabric helps with finding of non-redundant links and devices in the network in its diagrams section.
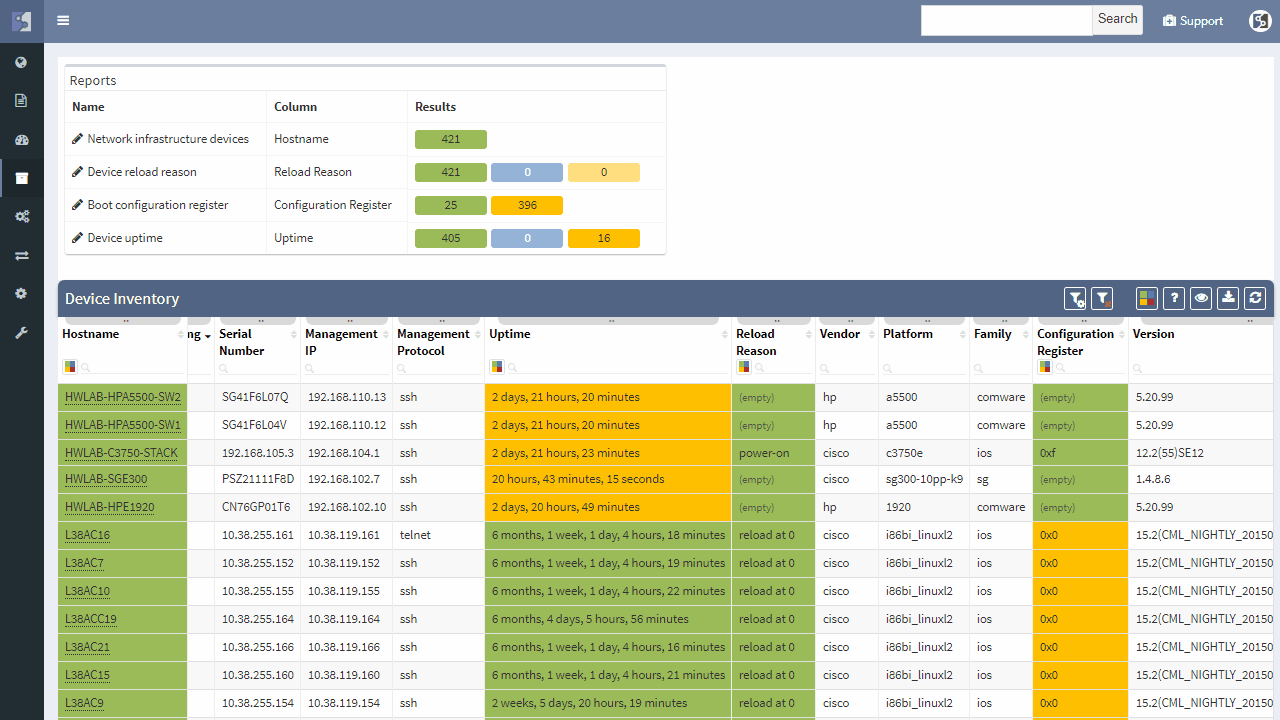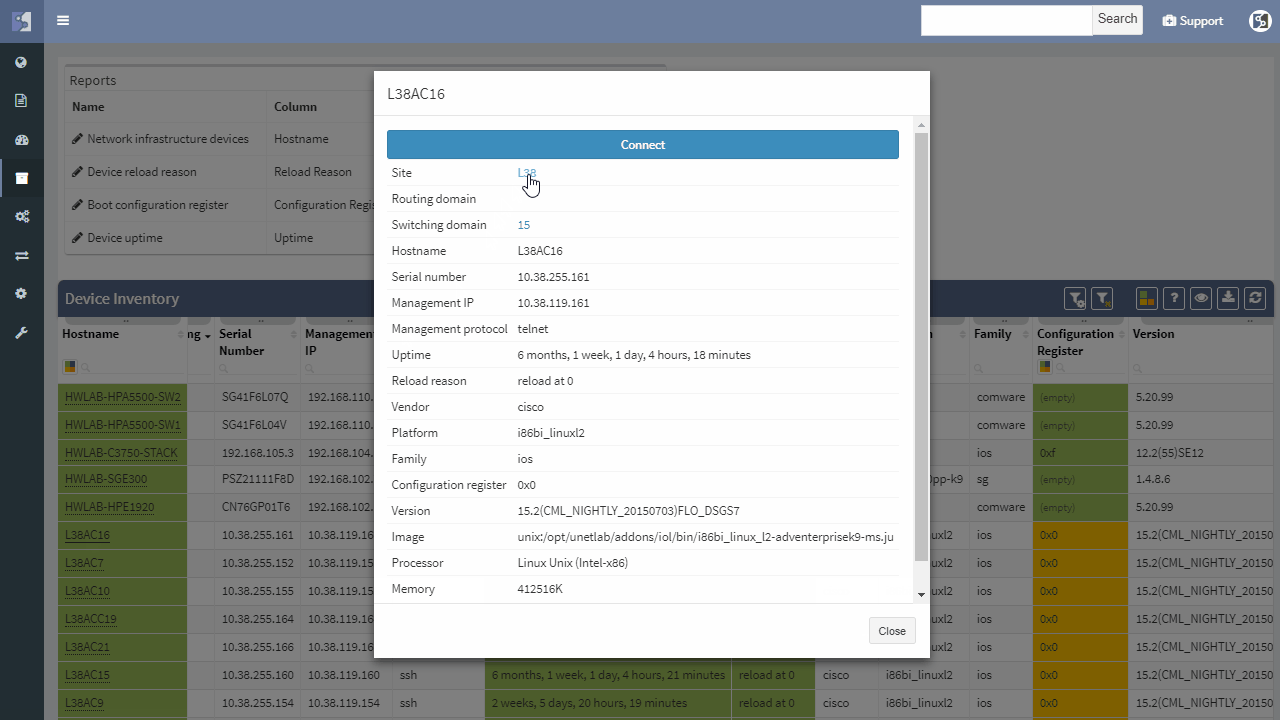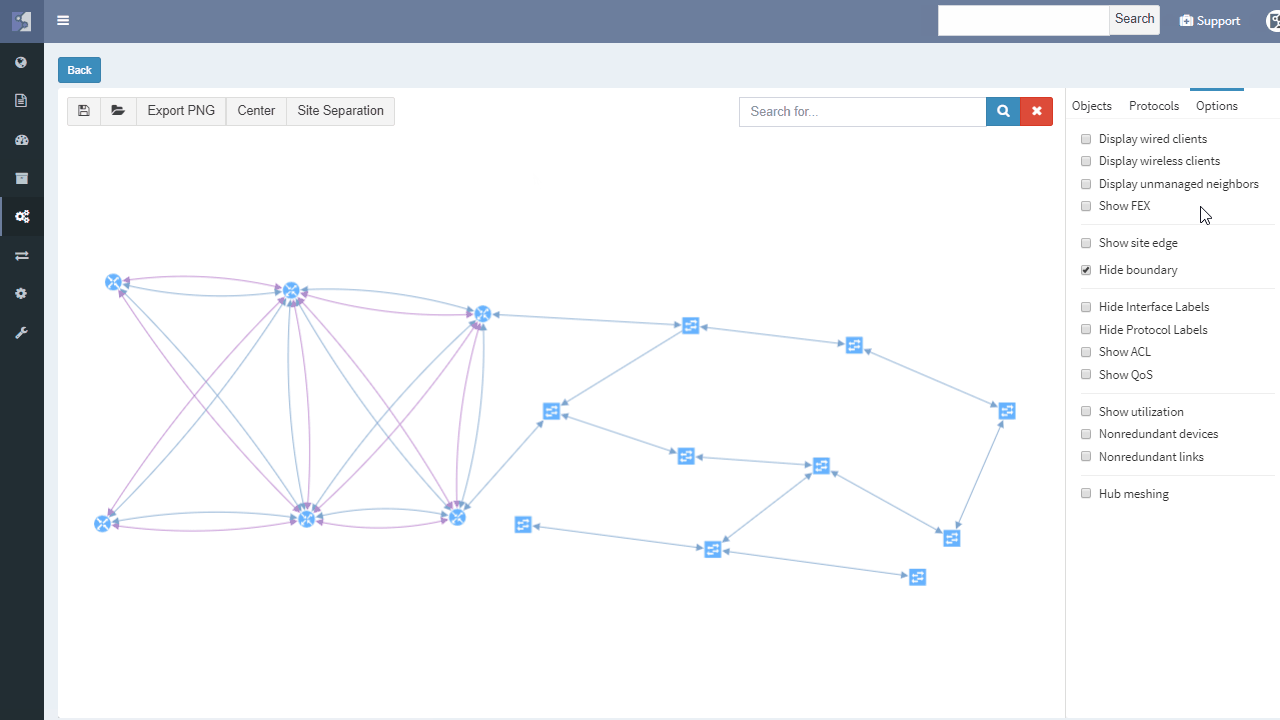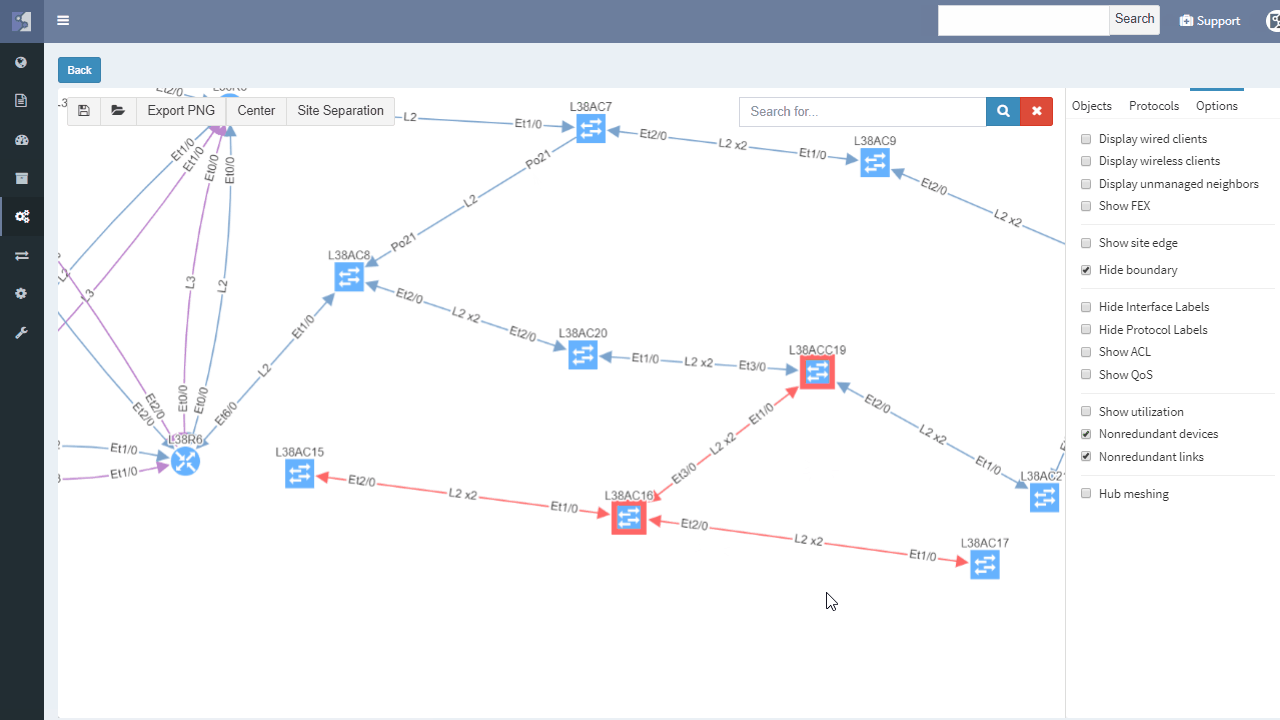
It does not matter if the SPOF is Layer 2 switch or Layer 3 router — those are all in the critical chain of application uptime. Device and links which form SPOF will be highlighted.
Additionally, networks with many small sites have automatic grouping of small sites into redundant and non-redundant groups in IP Fabric. Groups allow to easily spot sites with non-redundant transit connectivity.
If you’re interested in learning more about how IP Fabric’s platform can help you with analytics or intended network behavior reporting, contact us through our website, request a demo, follow this blog or sign up for our webinars.
Enterprise networks should never have Single Points of Failure (a.k.a SPOF) in their daily operation. SPOF in general is an element in a system which, if stopped, causes the whole system to stop.
Single failure (or maintenance or misconfiguration) of any network device or link should never put a network down and require manual intervention. Network architects know this rule and design the networks like that — placing redundant/backup devices and links which can take over all functions if the primary device/link fails.
But the reality is not always pleasant, and today’s operational networks can include SPOFs without anyone explicitly knowing. The reason is that even though the original design put all SPOFs away, the network may have evolved in the meantime, and new infrastructure may have been connected to it.
For example:
Part of the network operation activities should take into account that SPOFs may appear unexpectedly. This require advanced skills and lot of time to go trough routine settings and outputs if the networks is still resilient and high available. It also requires expensive disaster-recovery exercises to be performed regularly.
IP Fabric helps with finding of non-redundant links and devices in the network in its diagrams section.
It does not matter if the SPOF is Layer 2 switch or Layer 3 router — those are all in the critical chain of application uptime. Device and links which form SPOF will be highlighted.
Additionally, networks with many small sites have automatic grouping of small sites into redundant and non-redundant groups in IP Fabric. Groups allow to easily spot sites with non-redundant transit connectivity.
If you’re interested in learning more about how IP Fabric’s platform can help you with analytics or intended network behavior reporting, contact us through our website, request a demo, follow this blog or sign up for our webinars.