The network is a distributed system whose raison d'etre is to deliver applications to your users in a reliable and timely way. In order to keep your network up and functioning, manageable and supportable, adaptable and secure, you need to maintain a set of tools which take care of the myriad of different elements and vendors' platforms.
But how do you know the tools don't have conflicting views of the network devices they are responsible for? Are you sure they are all kept up to date and the information in them is accurate? Are there deeper questions about the network that you need the answers to and your tools just can't give you an answer?
IP Fabric can be used to enrich all of your network operations tooling. In this first of two parts, we'll take a look at just what comprises that ecosystem - and where the gaps are that IP Fabric can fill!
In order to ensure your network is maintained and well supported, you need to make use of tooling in a number of areas:
Each of these areas can break down further into toolsets used by a range of different folks in order to maintain network service.
Even in these days where network automation is de rigeur, a large majority of configuration changes are still made manually through device command line interfaces (CLI). It is typical though to use Configuration Management tooling to at least back up that configuration when changes are made. This allows simple replacement of a device should one fail, and the ability to track change activity over time.
Over time though, configuration of network devices is becoming more automated, typically through use of

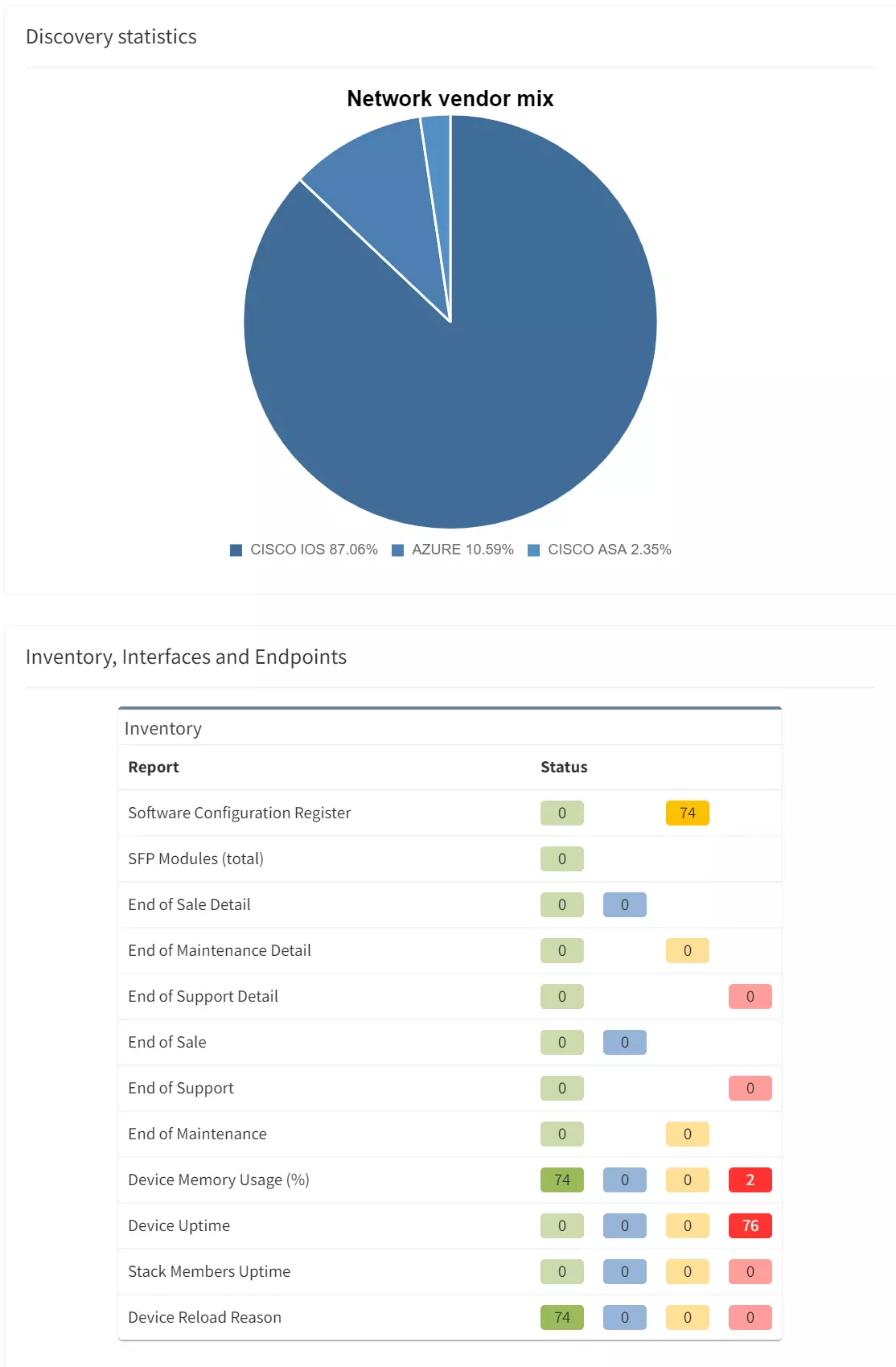
In order to get a full view, multiple tools may be required across a network, due to the different network domains and selection of vendors within an environment. Ideally they should all be synchronised in some form to ensure complete visibility and coverage end-to-end.
Once a network has been deployed, it is necessary to ensure it is monitored - that the performance of the components is tracked and reported on, to ensure that capacity limits aren't reached and performance thresholds aren't breached. These typically address three main areas:
More modern approaches to gathering performance data include streaming telemetry. A data collection platform subscribes to certain types of performance data from a publisher (typically a network device or controller). The data is then sent directly without a need to poll for it, meaning that it arrives at the collector in something approximating real time.
Performance monitoring can only give a view of individual device, link or applications. Again, multiple tools may be required due to mixes of vendors and capabilities, and it may be difficult to offer a meaningful aggregated view. Maintaining end-to-end visibility and consistency is once more key.
Alongside performance monitoring, systems to collect information about events occurring in the network are key, in order to provide a responsive service. There are a number of mechanisms for collection of event data, including:
From a network-wide perspective, the key element to event management is Correlation. An incident in the network has the potential to generate events on a number of devices and as such may appear as a number of SNMP traps, log entries or webhooks in the collection engine. An Event Correlation engine (such as a SIEM - Security Incident Event Management platform) will combine those notifications and attempt to derive a root cause from them.
It is important to be sure that all elements in the network are contributing event data. This is important particularly when you are using correlation to determine root cause of issues. Traditional tooling doesn't verify this, we need to combine a picture of what is really in the network with whether it is correctly configured.
Books have been written on this topic alone, so I shan't delve too deeply, but there are a few key areas in service management which really impact day to day network operations. For example:
It is clear that for ITSM processes, the more information about interaction of application service with the infrastructure that supports it is best - difficult to derive from simple monitoring platforms. Documentation also needs to be kept updated to support pre- and post-change validation.
The CMDB - or Configuration Management Database - is a bit of a misnomer as far as network support is concerned. It isn't concerned with management of device configurations, but with being a definitive inventory of all the items which make up the network infrastructure. It is used by all areas of the business which need access and visibility to that information, and includes:
These elements are not directly related to the operation of the network infrastructure itself (although licensing is becoming more so) but are key to ensuring that support runs smoothly over time. Too often manual processes are used to keep data in sync with these operational platforms.
You can see that in order to operate networks, a whole web of tooling is required to maintain a good level of visibility and control. Importantly, the significant gaps between them need to be filled. In Part Two of this mini-series, we'll show how IP Fabric can be used to answer questions that you simply can't answer with the traditional tooling we describe here. And we will look at how we can enrich the data in those tools with information from IP Fabric!
The network is a distributed system whose raison d'etre is to deliver applications to your users in a reliable and timely way. In order to keep your network up and functioning, manageable and supportable, adaptable and secure, you need to maintain a set of tools which take care of the myriad of different elements and vendors' platforms.
But how do you know the tools don't have conflicting views of the network devices they are responsible for? Are you sure they are all kept up to date and the information in them is accurate? Are there deeper questions about the network that you need the answers to and your tools just can't give you an answer?
IP Fabric can be used to enrich all of your network operations tooling. In this first of two parts, we'll take a look at just what comprises that ecosystem - and where the gaps are that IP Fabric can fill!
In order to ensure your network is maintained and well supported, you need to make use of tooling in a number of areas:
Each of these areas can break down further into toolsets used by a range of different folks in order to maintain network service.
Even in these days where network automation is de rigeur, a large majority of configuration changes are still made manually through device command line interfaces (CLI). It is typical though to use Configuration Management tooling to at least back up that configuration when changes are made. This allows simple replacement of a device should one fail, and the ability to track change activity over time.
Over time though, configuration of network devices is becoming more automated, typically through use of
In order to get a full view, multiple tools may be required across a network, due to the different network domains and selection of vendors within an environment. Ideally they should all be synchronised in some form to ensure complete visibility and coverage end-to-end.
Once a network has been deployed, it is necessary to ensure it is monitored - that the performance of the components is tracked and reported on, to ensure that capacity limits aren't reached and performance thresholds aren't breached. These typically address three main areas:
More modern approaches to gathering performance data include streaming telemetry. A data collection platform subscribes to certain types of performance data from a publisher (typically a network device or controller). The data is then sent directly without a need to poll for it, meaning that it arrives at the collector in something approximating real time.
Performance monitoring can only give a view of individual device, link or applications. Again, multiple tools may be required due to mixes of vendors and capabilities, and it may be difficult to offer a meaningful aggregated view. Maintaining end-to-end visibility and consistency is once more key.
Alongside performance monitoring, systems to collect information about events occurring in the network are key, in order to provide a responsive service. There are a number of mechanisms for collection of event data, including:
From a network-wide perspective, the key element to event management is Correlation. An incident in the network has the potential to generate events on a number of devices and as such may appear as a number of SNMP traps, log entries or webhooks in the collection engine. An Event Correlation engine (such as a SIEM - Security Incident Event Management platform) will combine those notifications and attempt to derive a root cause from them.
It is important to be sure that all elements in the network are contributing event data. This is important particularly when you are using correlation to determine root cause of issues. Traditional tooling doesn't verify this, we need to combine a picture of what is really in the network with whether it is correctly configured.
Books have been written on this topic alone, so I shan't delve too deeply, but there are a few key areas in service management which really impact day to day network operations. For example:
It is clear that for ITSM processes, the more information about interaction of application service with the infrastructure that supports it is best - difficult to derive from simple monitoring platforms. Documentation also needs to be kept updated to support pre- and post-change validation.
The CMDB - or Configuration Management Database - is a bit of a misnomer as far as network support is concerned. It isn't concerned with management of device configurations, but with being a definitive inventory of all the items which make up the network infrastructure. It is used by all areas of the business which need access and visibility to that information, and includes:
These elements are not directly related to the operation of the network infrastructure itself (although licensing is becoming more so) but are key to ensuring that support runs smoothly over time. Too often manual processes are used to keep data in sync with these operational platforms.
You can see that in order to operate networks, a whole web of tooling is required to maintain a good level of visibility and control. Importantly, the significant gaps between them need to be filled. In Part Two of this mini-series, we'll show how IP Fabric can be used to answer questions that you simply can't answer with the traditional tooling we describe here. And we will look at how we can enrich the data in those tools with information from IP Fabric!