The fundamental purpose of a data network is to connect users with applications, data producers and consumers with storage. The most desirable feature of a network is to maximise availability of those services to the endpoints that consume them. In order to achieve that, we need to consider (amongst other things):
To be sure we can deliver availability then, we should design our networks with these tenets in mind.
Sometimes though, organic growth in your IT environment means that the original design principles can't be upheld. You need to change your network to fulfil a new requirement and fast! And so you build a change to your network that compromises the original design principles but provides a solution.
Often, this means connecting a new link to a new device which is not big enough, fast enough or resilient. Or some unseen configuration issue prevents redundant links from being available for use. Then, when an issue occurs later, you and your users suffer because the principles you laid out for maximising availability haven't been upheld and systems fall over. You are then left trying to trace the reason why things have failed.
Where do you start? Your diagrams and design documents were great when you built your network, but no one has kept them updated. And so, you have to start where they end, and:
then you sit down with your network team to analyse where your single points of failure are and what you can do about them. Don't forget that they might not be immediately obvious in the physical topology, but in the logical configuration!
Alternatively you could give the job to IP Fabric.
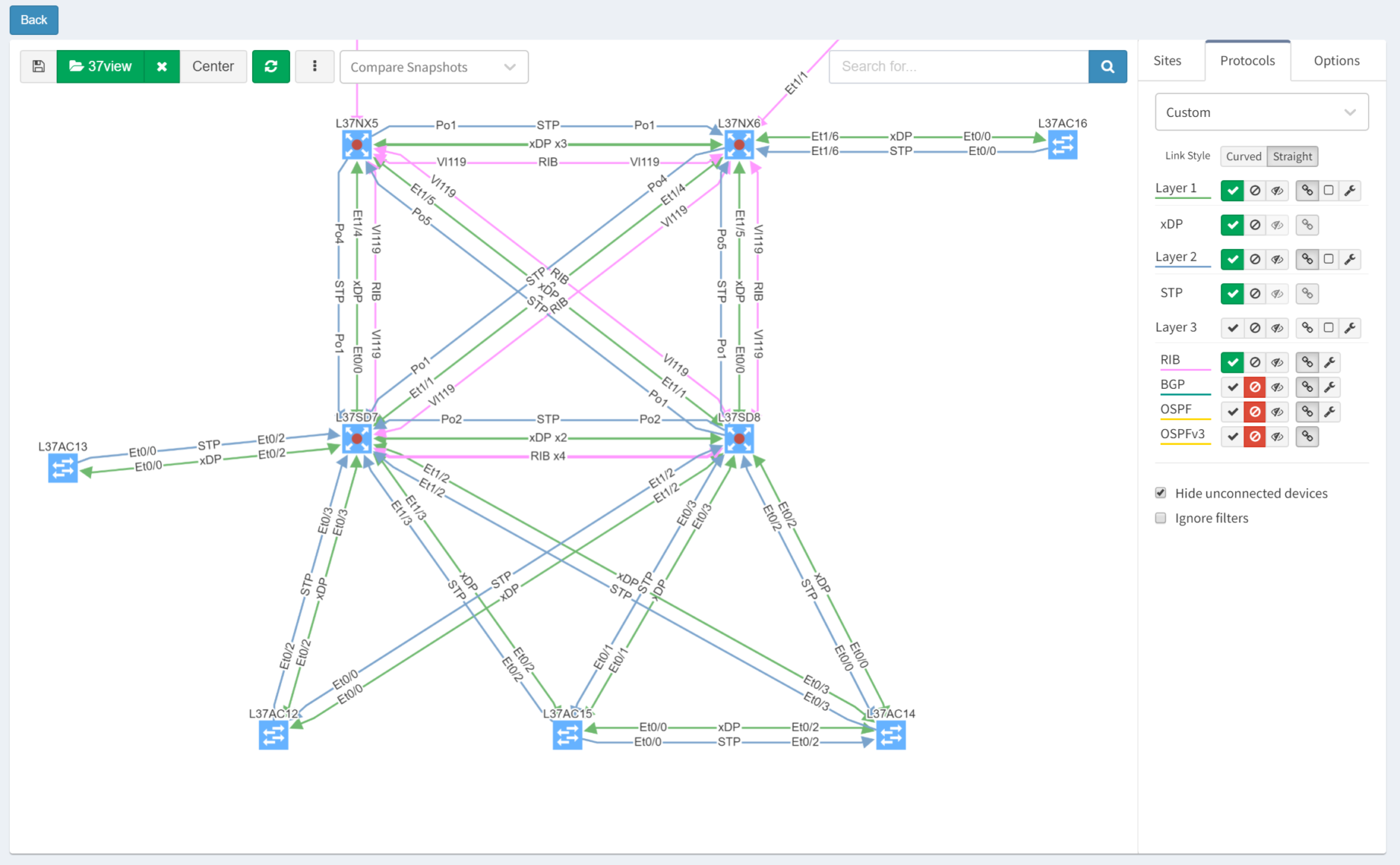
Each time IP Fabric runs a snapshot, it rediscovers the network topology from the physical layer upwards. Clicking through the Diagram | Site Diagrams menu shows a visualisation of the topology:
After turning off Layers 1 and 3 for clarity, then selecting the Options tab and clicking "Single Points of Failure", IP Fabric highlights them with red outlines:
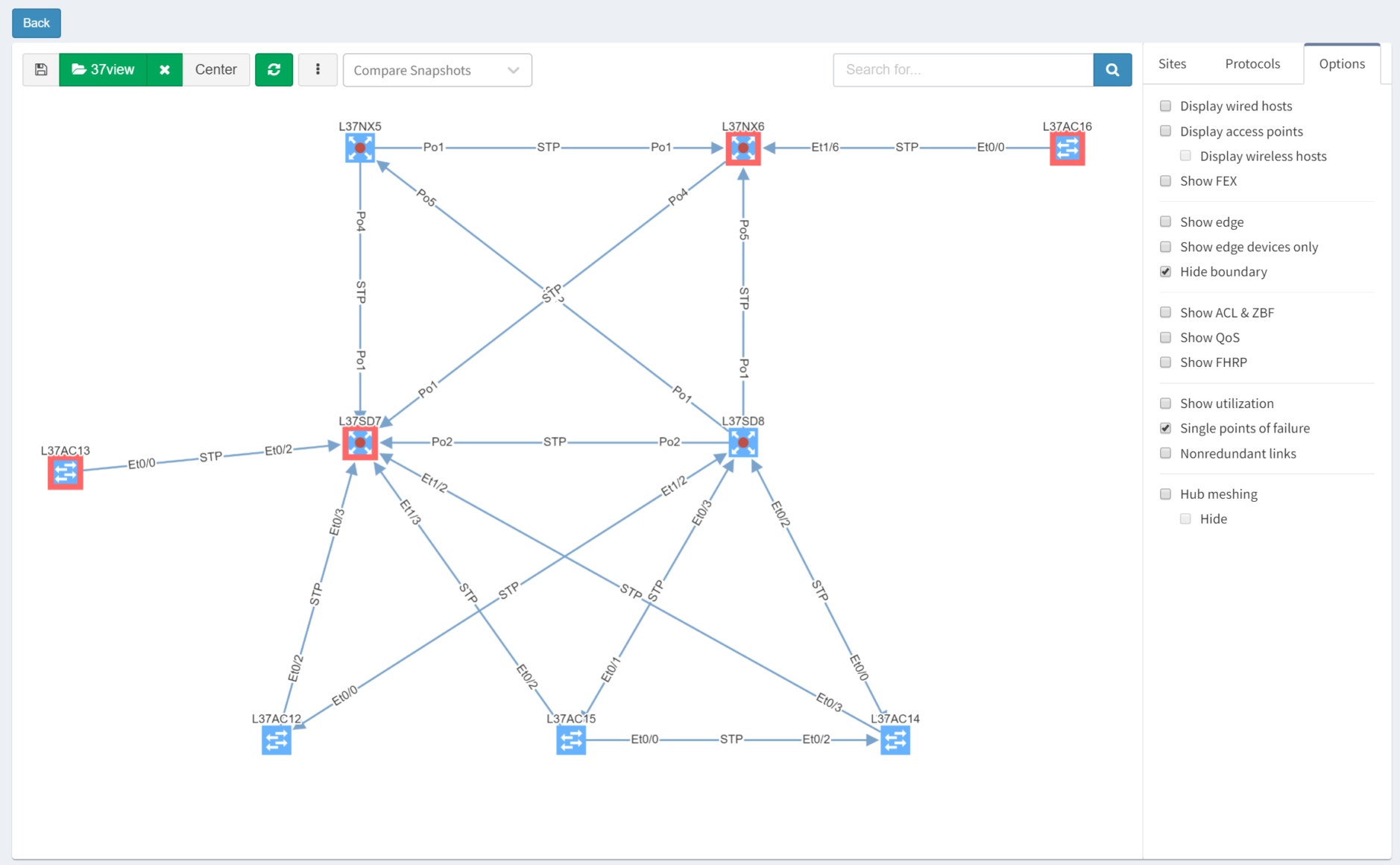
IP Fabric is able to analyse and interpret relationships between devices both upstream and downstream. In this case, switches are shown as SPOFs because they are the sole upstream devices for some access switches.
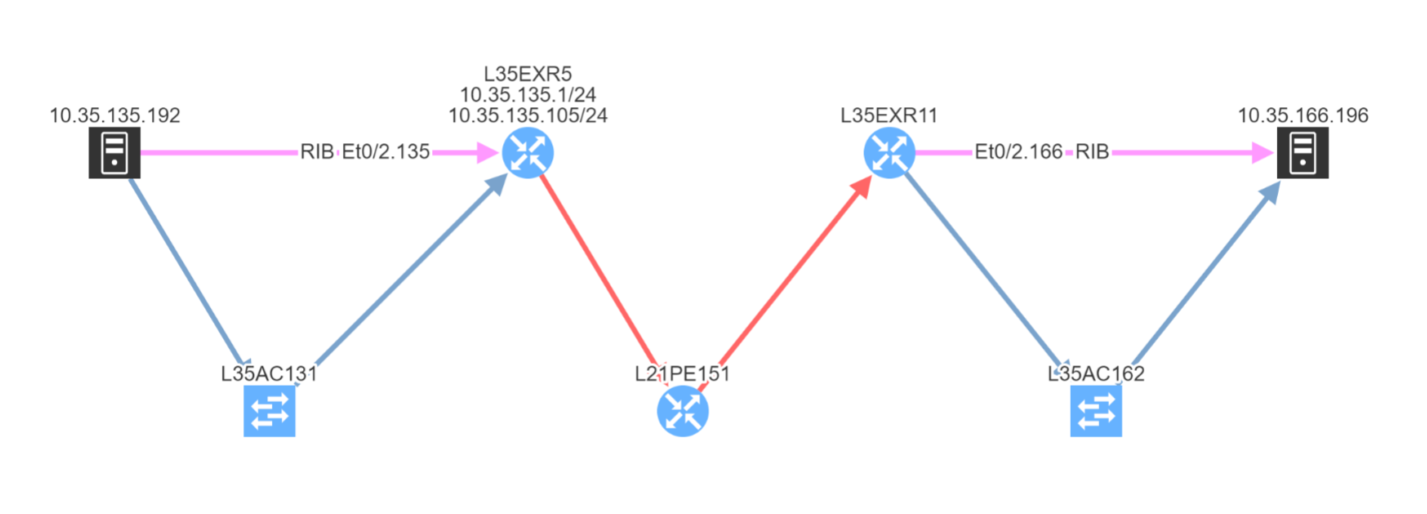
As we've seen, IP Fabric's powerful visualisation helps us appreciate problems in topologies, but there are alternative and equally powerful views of the network. For example, you can check a simulated path between hosts for single points of failure. Select Diagrams | End-to-end path. After submitting source and destination IPs, non-redundant devices can be highlighted along the path.
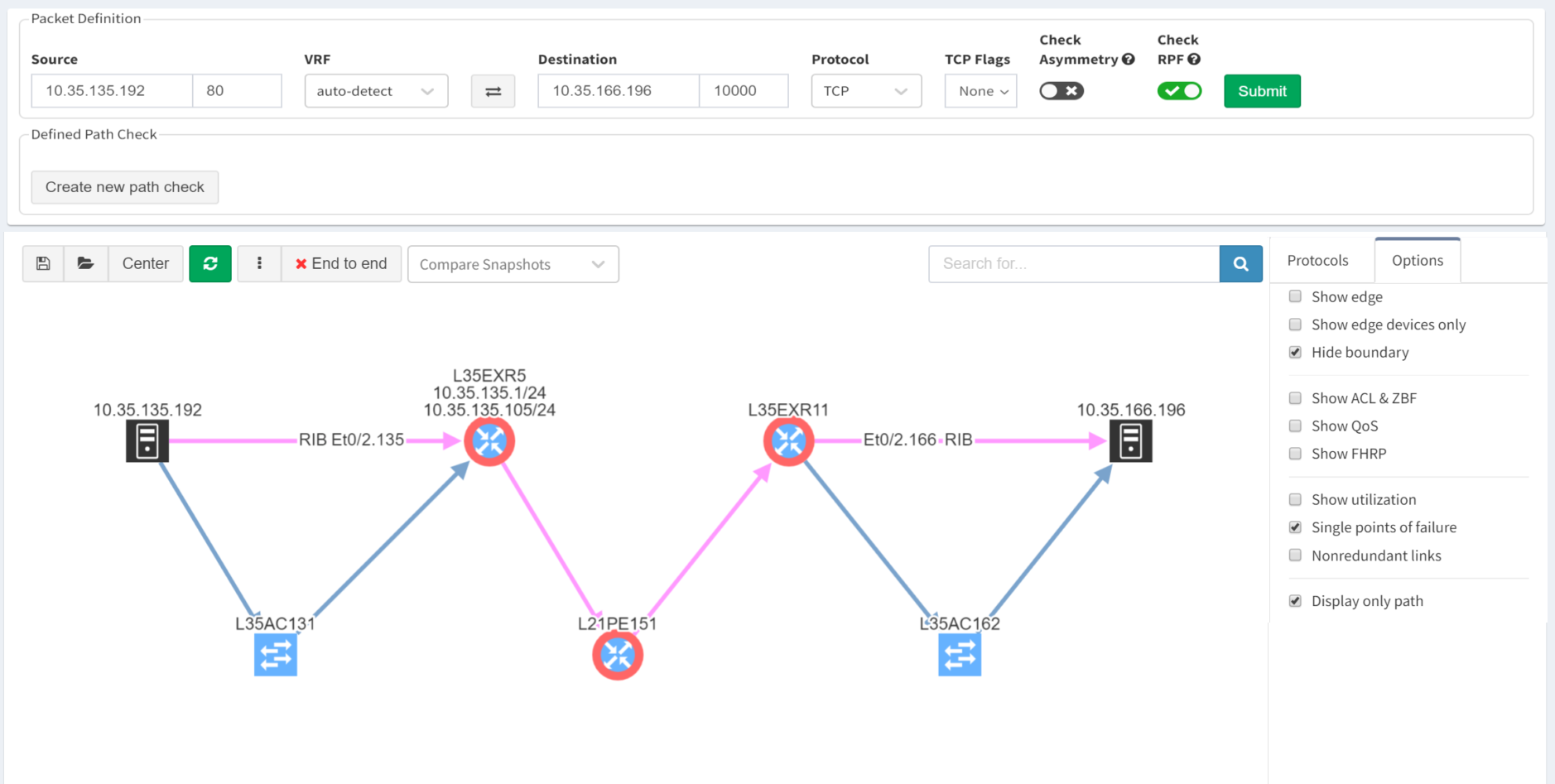
Subtly different, you are also able to highlight non-redundant links, showing where there is a strict dependency on the link to ensure an end-to-end path between the hosts.
So you can see how IP Fabric has saved you huge amounts of time and effort spotting single points of failure in your network topology. And now you are in a position to proactively remediate before this becomes a problem!
If you have found this article helpful, please follow our company’s LinkedIn or Blog, where more content will be emerging. If you would like to test our solution to see for yourself how IP Fabric can help you manage your network more effectively, please contact us through www.ipfabric.io.
The fundamental purpose of a data network is to connect users with applications, data producers and consumers with storage. The most desirable feature of a network is to maximise availability of those services to the endpoints that consume them. In order to achieve that, we need to consider (amongst other things):
To be sure we can deliver availability then, we should design our networks with these tenets in mind.
Sometimes though, organic growth in your IT environment means that the original design principles can't be upheld. You need to change your network to fulfil a new requirement and fast! And so you build a change to your network that compromises the original design principles but provides a solution.
Often, this means connecting a new link to a new device which is not big enough, fast enough or resilient. Or some unseen configuration issue prevents redundant links from being available for use. Then, when an issue occurs later, you and your users suffer because the principles you laid out for maximising availability haven't been upheld and systems fall over. You are then left trying to trace the reason why things have failed.
Where do you start? Your diagrams and design documents were great when you built your network, but no one has kept them updated. And so, you have to start where they end, and:
then you sit down with your network team to analyse where your single points of failure are and what you can do about them. Don't forget that they might not be immediately obvious in the physical topology, but in the logical configuration!
Alternatively you could give the job to IP Fabric.
Each time IP Fabric runs a snapshot, it rediscovers the network topology from the physical layer upwards. Clicking through the Diagram | Site Diagrams menu shows a visualisation of the topology:
After turning off Layers 1 and 3 for clarity, then selecting the Options tab and clicking "Single Points of Failure", IP Fabric highlights them with red outlines:
IP Fabric is able to analyse and interpret relationships between devices both upstream and downstream. In this case, switches are shown as SPOFs because they are the sole upstream devices for some access switches.
As we've seen, IP Fabric's powerful visualisation helps us appreciate problems in topologies, but there are alternative and equally powerful views of the network. For example, you can check a simulated path between hosts for single points of failure. Select Diagrams | End-to-end path. After submitting source and destination IPs, non-redundant devices can be highlighted along the path.
Subtly different, you are also able to highlight non-redundant links, showing where there is a strict dependency on the link to ensure an end-to-end path between the hosts.
So you can see how IP Fabric has saved you huge amounts of time and effort spotting single points of failure in your network topology. And now you are in a position to proactively remediate before this becomes a problem!
If you have found this article helpful, please follow our company’s LinkedIn or Blog, where more content will be emerging. If you would like to test our solution to see for yourself how IP Fabric can help you manage your network more effectively, please contact us through www.ipfabric.io.