Typically, an organization's network isn't a single thing. It's a collection, a network of networks if you will, which work together to deliver the connectivity from user to app, from sensor to data repository, which underpins application service for an organization.
There are networks of different types, using different technologies, connecting different domains, using multiple vendors; each must be interconnected and interoperable in order to deliver the packets which carry application data from application workload to user. The number and depth of these interactions bring complexity to the network of networks and with it being dynamic and alive, this complexity grows daily.
The biggest challenge that modern network teams face is managing that complexity, along with the scale that adoption of connected applications has brought to the modern IT landscape. And as network engineers, not only are we constantly reminded that the best way to cope is to automate, but we recognize the necessity.
The idea is to maintain a centralized management point for the network which can provision service and deploy change using as few touchpoints as possible. Typically, that might mean introducing:
These approaches all have pros and cons of course, but typically are very focused on delivering an outcome for a specific task, for a specific vendor's equipment, or in a specific network domain. As such, testing of success of automation tends to be focused and task-based too. And while this has a certain level of value in ensuring that tasks themselves aren't broken, it's hard to verify that the impact of change to the network isn't farther reaching, or that further change is required to enable the capability we’re trying to introduce.
Consider the case where you create a new subnet in your private Cloud instance – this is easily verified that it has happened through the API into your favorite Cloud provider. But does that mean it is available and usable? Not necessarily – we might need to make sure it is advertised into our on-prem network, redistributed over our SDWAN into our campus, and that policy is updated to allow traffic to pass to it.
Network Assurance has the goal of validating that the network is operating the way you intend it to and enabling corrective action when your dynamically changing network drifts too far from your intended state. Importantly, the scope for network assurance is the whole network end-to-end, not limited to a specific vendor or domain.
By using IP Fabric's automated network assurance platform, it's possible to validate:
IP Fabric uses snapshots of this model to build up a picture of changes across the network over time. Those snapshots can be of the complete network, scheduled regularly, or they can be ad hoc or partial views, depending on the desired effect (particularly useful before and after change implementation).
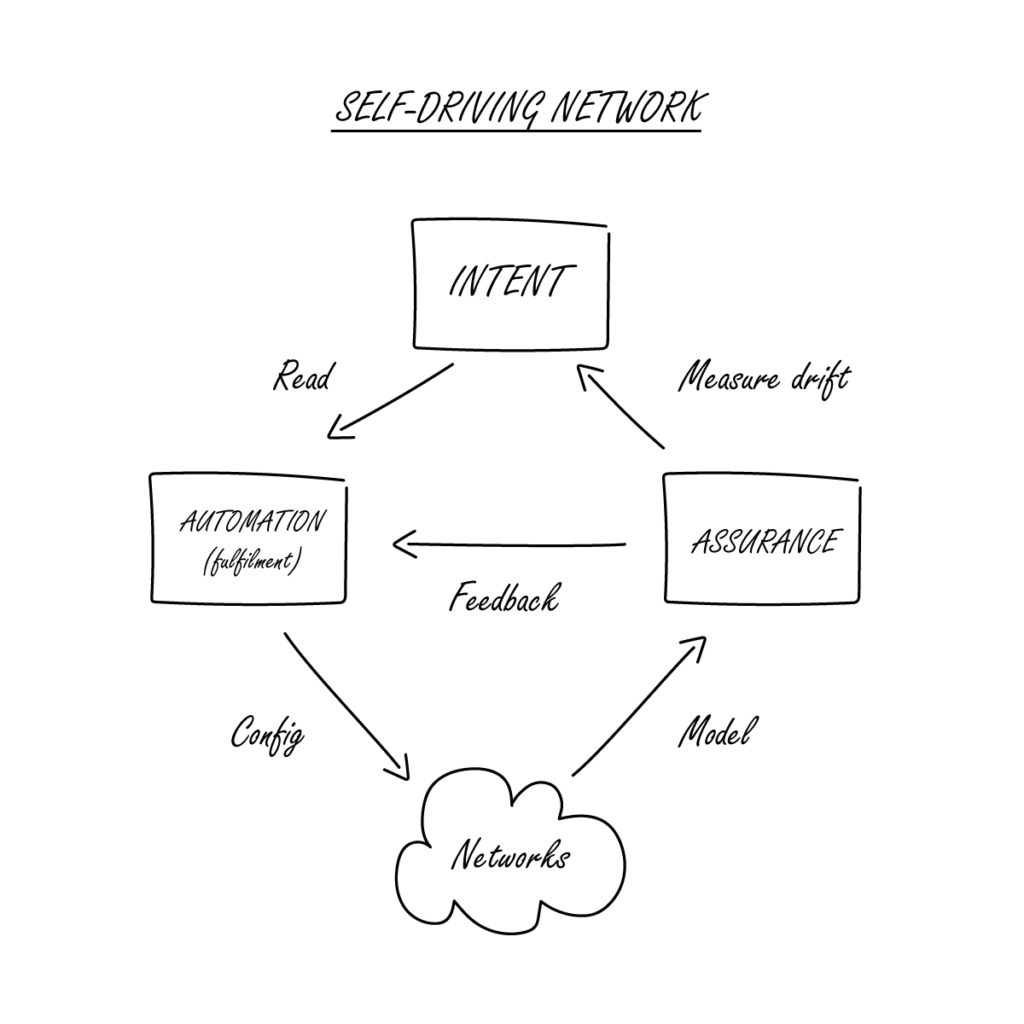
And this is the key. When changes are made in the network, it is not likely to be enough to simply test that the desired configuration has been pushed to the device. The impact of that change is likely to be felt further afield and so it is necessary to look more holistically at the outcome, as looking at the change in isolation can be misleading. Is a successful config push successful if it’s impacted your network elsewhere, and therefore your end-to-end service?
You can examine the state of the affected device and that may help but in reality, the best outcome is to validate that once tasks are completed, the overall change has had the desired impact on end-to-end service. And naturally, the only way to accurately verify that end-to-end behavior will be as expected is to not limit the scope but test against a model of the whole network.
And as IP Fabric's API allows snapshot creation and refresh, along with querying of those tests, it is the perfect tool to incorporate into an automated workflow to carry out that big picture validation.
Recently, the IP Fabric team was in Las Vegas, where we shared the stage with Itential at Tech Field Day Extra at Cisco Live 2022. We showcased what it means to integrate network assurance into real network automation processes, and how that turns Network Automation from a point solution to a small problem, into a key component of the complete Self-Driving Network.

Watch the Tech Field Day video below to see exactly how smart integrations can accelerate your network automation:
WATCH: Scaling Network Automation (with Itential)
WATCH: Closing the Loop with Network Assurance (with IP Fabric)
WATCH: Integrated Network Automation and Assurance Demo with Itential & IP Fabric
BGP is famously known for being the routing protocol of the internet, but not only. A lot of companies are using BGP in their internal network. One of the main reasons for that: it allows great control and flexibility with routing exchange.
As with any routing protocol and critical connectivity, we want to ensure we are resilient to failure and that the resiliency is operational. With BGP, to do so, we need to have a closer look at the received prefixes.
Let's take a classic example, where you would have two devices connected to an external party. This could be your ISP, MPLS provider…
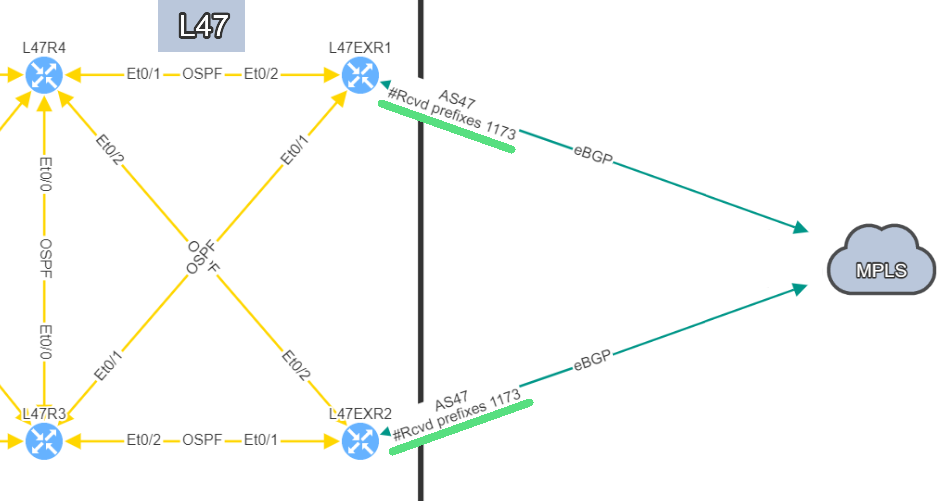
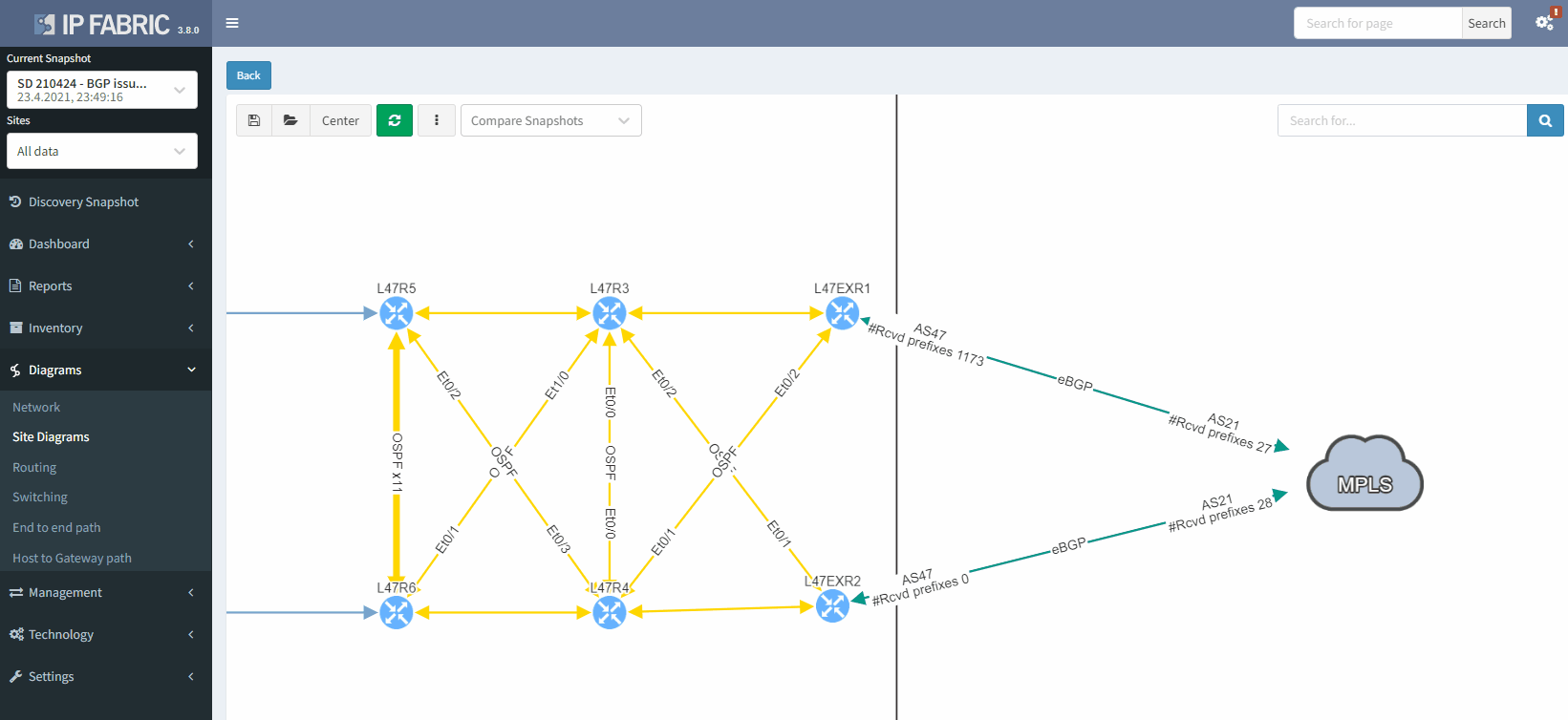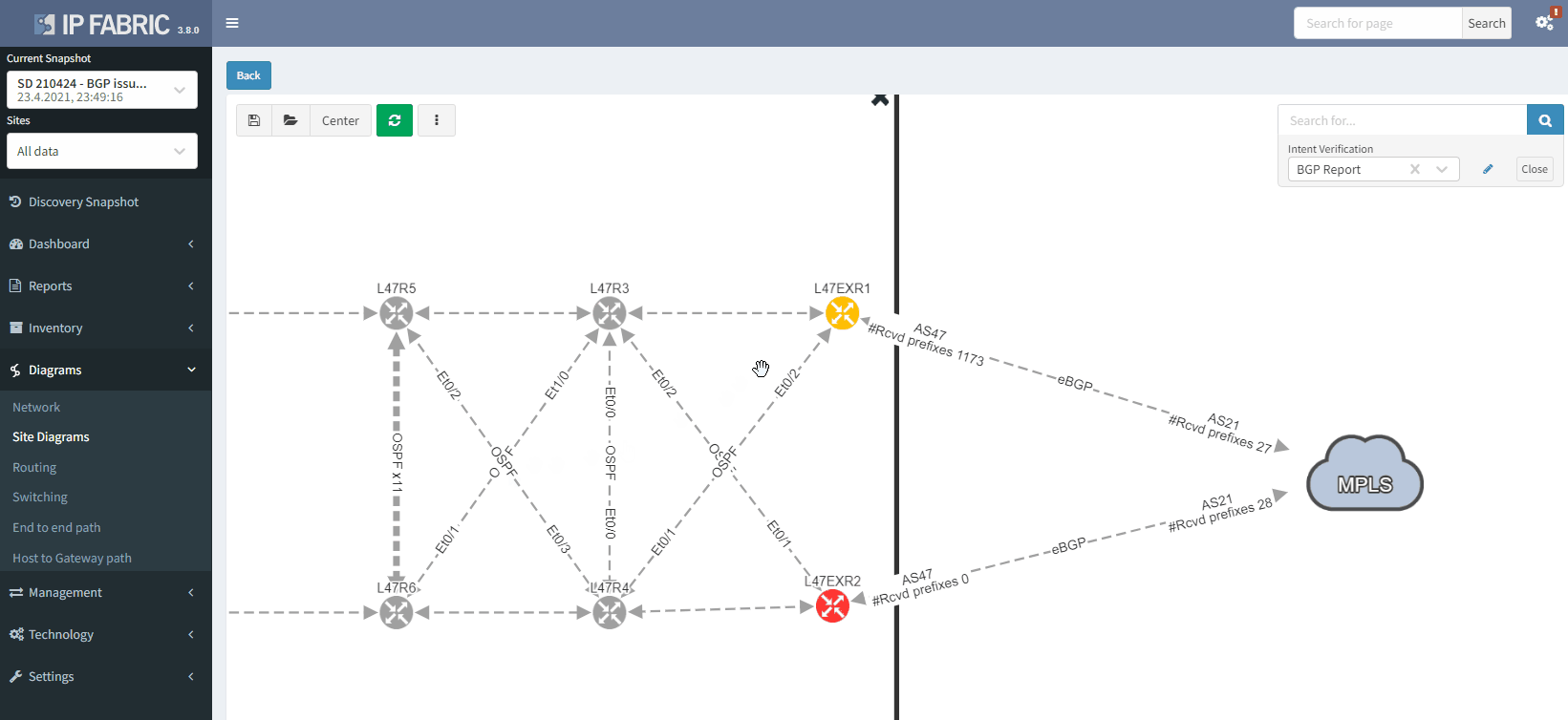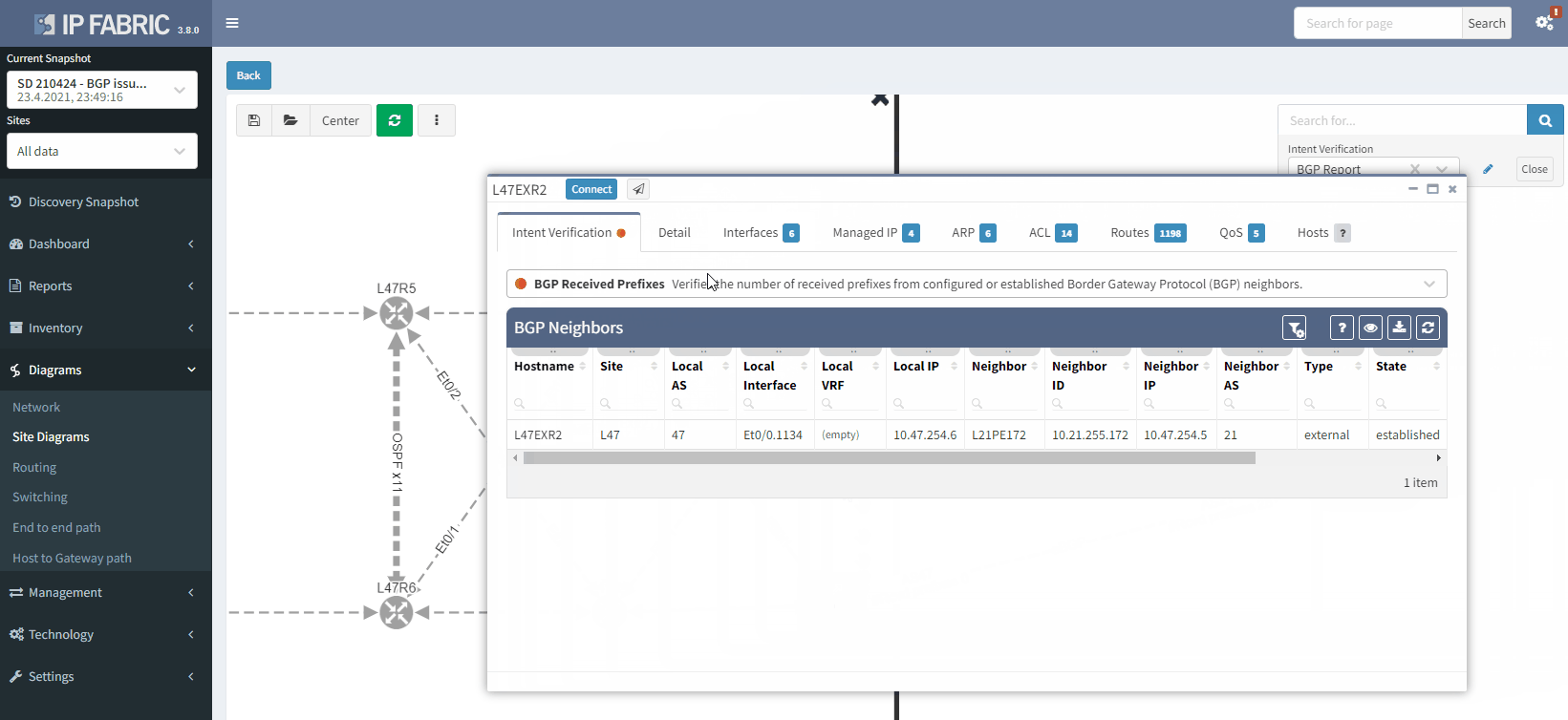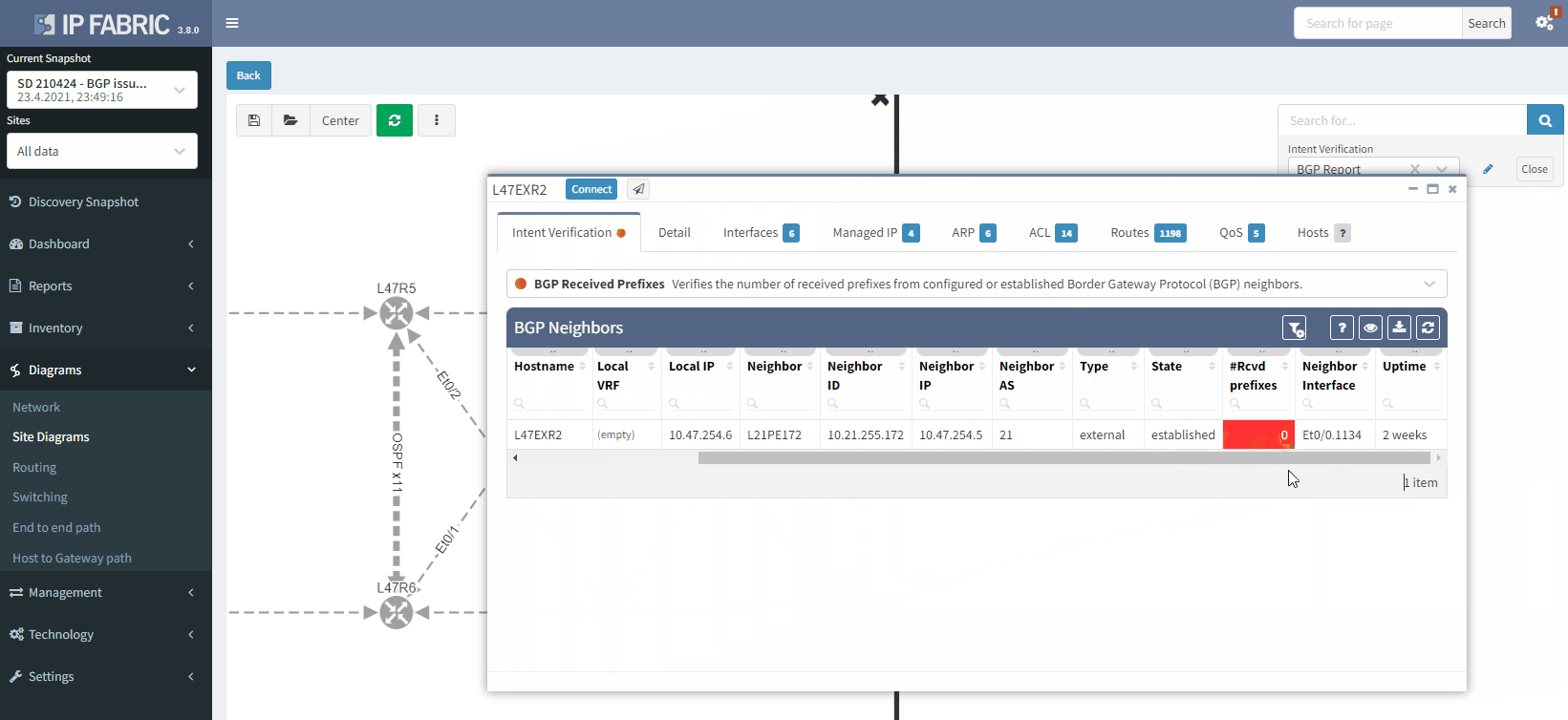
In this example, site L47, on the left, is connected to site L21 which is your MPLS cloud.
You have your two eBGP sessions established with the MPLS cloud, that's great! Now you want to ensure that you are resilient by checking the receive routes from the provider on both links. This is how you will be able to reach any of your sites connected to the MPLS cloud.
In this situation, if one link fails, you have full resiliency. You will not lose connectivity to your MPLS network and all the services hosted outside site L47.
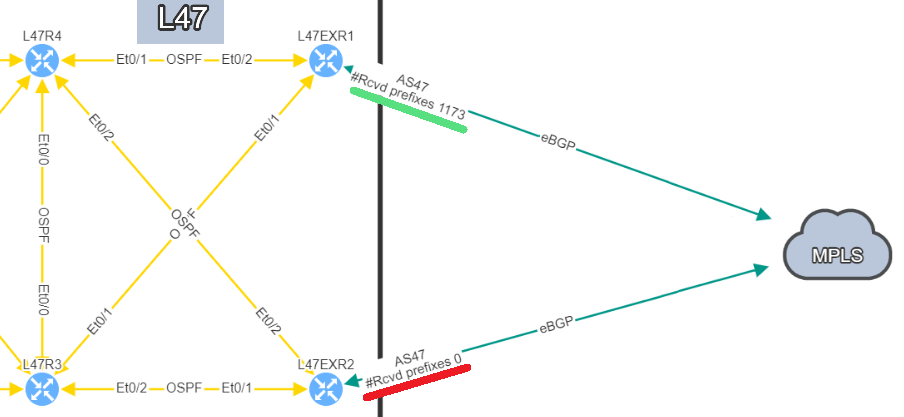
In this situation, if you lose L47EXR1 or the link between this router and site L21, your secondary link will not be able to forward any traffic. L47EXR2 is not receiving any routes.
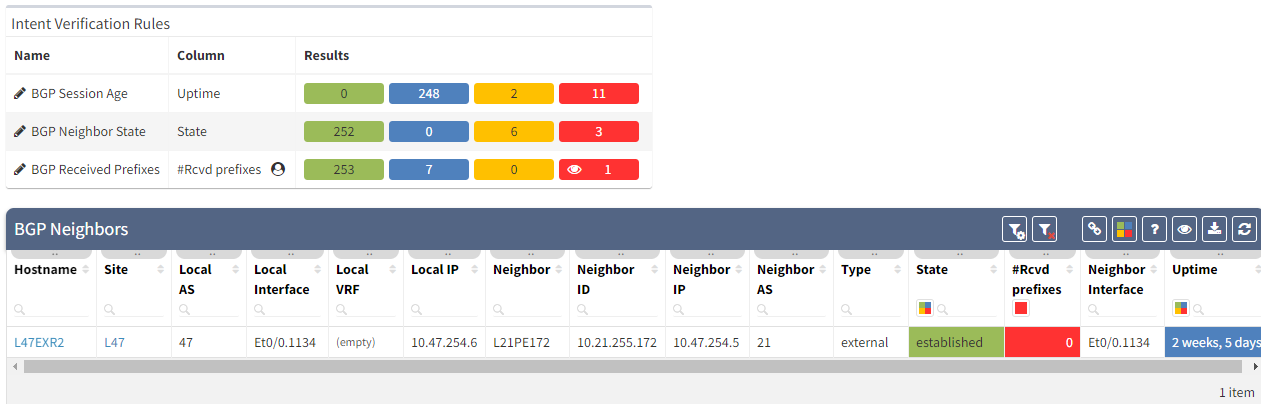
This is what you would see on your device:

The fact that you can see State/PfxRcd showing "0" tells you the BGP session is established, otherwise, you would see the current state (Idle, Active...). Any other number would be good, unfortunately in this scenario, you are not receiving any route.

You are now in a situation where you do not have any resiliency, and your monitoring system is not alerting us on the issue.
That’s a very good question! In a situation like this one, the BGP session is not affected, which means there is no error generated by the router. The device will not send Syslog messages or SNMP traps to inform your monitoring system that you are not receiving any routes.
That's where IP Fabric can play a crucial role to identify the issue quickly before it causes any damages. There are several ways to see the problem:
The IP Fabric dashboard provides an overview of the network analysis results, including issues and links to the detailed reports.
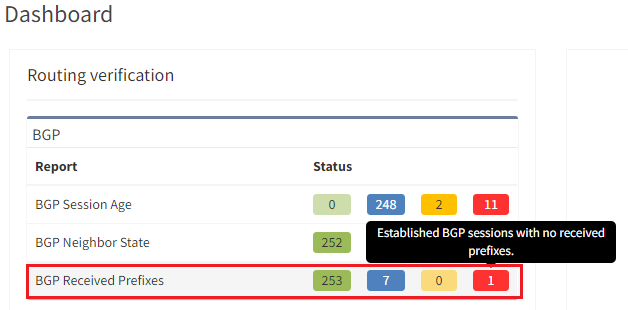
After seeing this table, you will want to check further details regarding the issue. Just click on the interesting number, and you will be redirected to the appropriate technology page and the intent verifications.
As we have seen at the beginning, you will be able to check directly on the diagram the number of received prefixes for a specific neighbor.
It's also possible to display on the diagram the verification information from all the supported technologies. In this example, we will add the BGP information on the diagram for site 47:
The moment we select the verification to add to the diagram, we can see L47EXR2 becomes red. If we click on the device, we will see the explanation on why it's showing red:
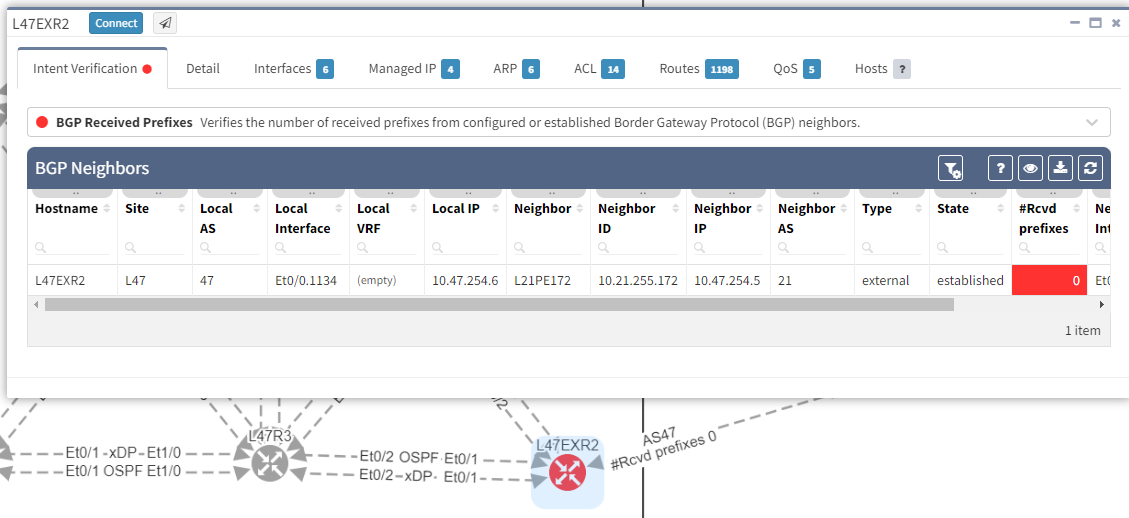
In addition, we can spot this issue by looking at the end-to-end path. Let's take an example where we are looking at the path from a source in site L47 to a destination in site L66, which is connected to the MPLS cloud.
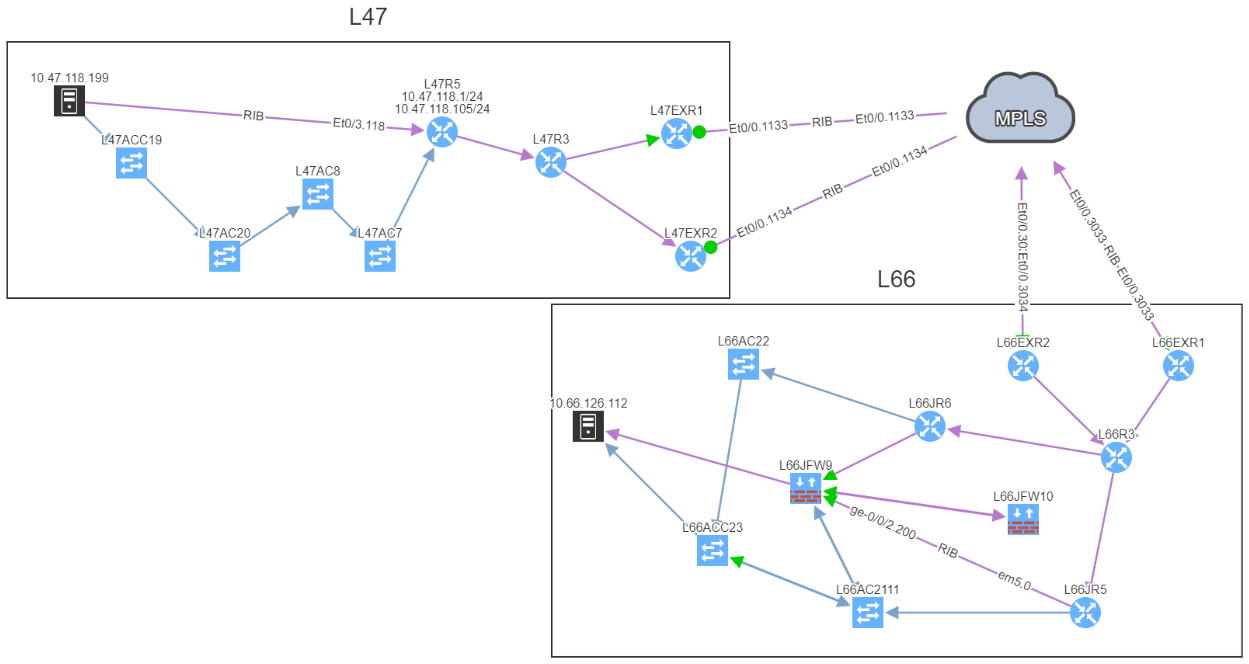
In a normal situation, we would expect to see the traffic being able to use both links to reach the MPLS cloud:
If we now compare with the snapshot where we have the issue, we can clearly see that we have lost our resiliency:
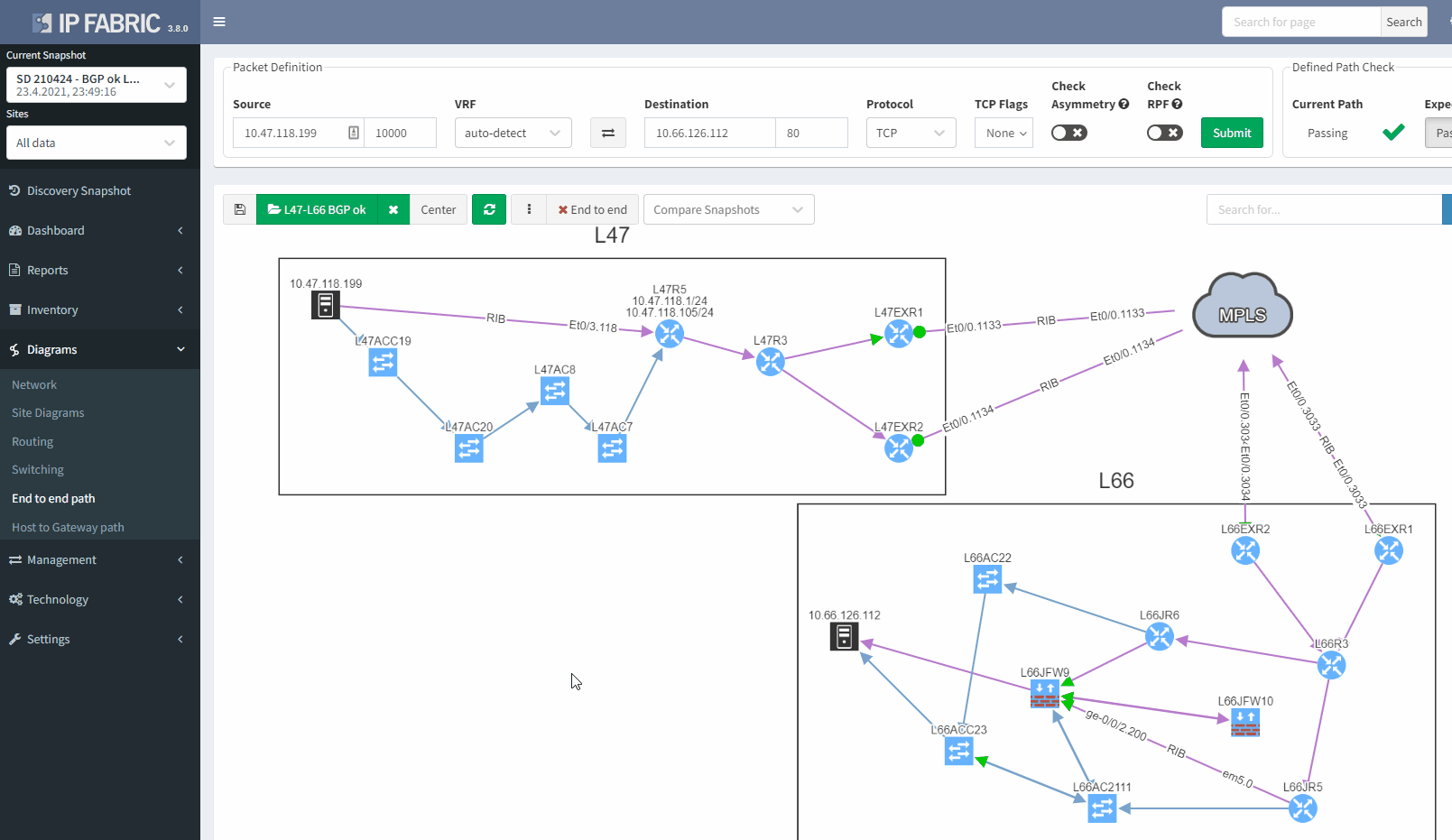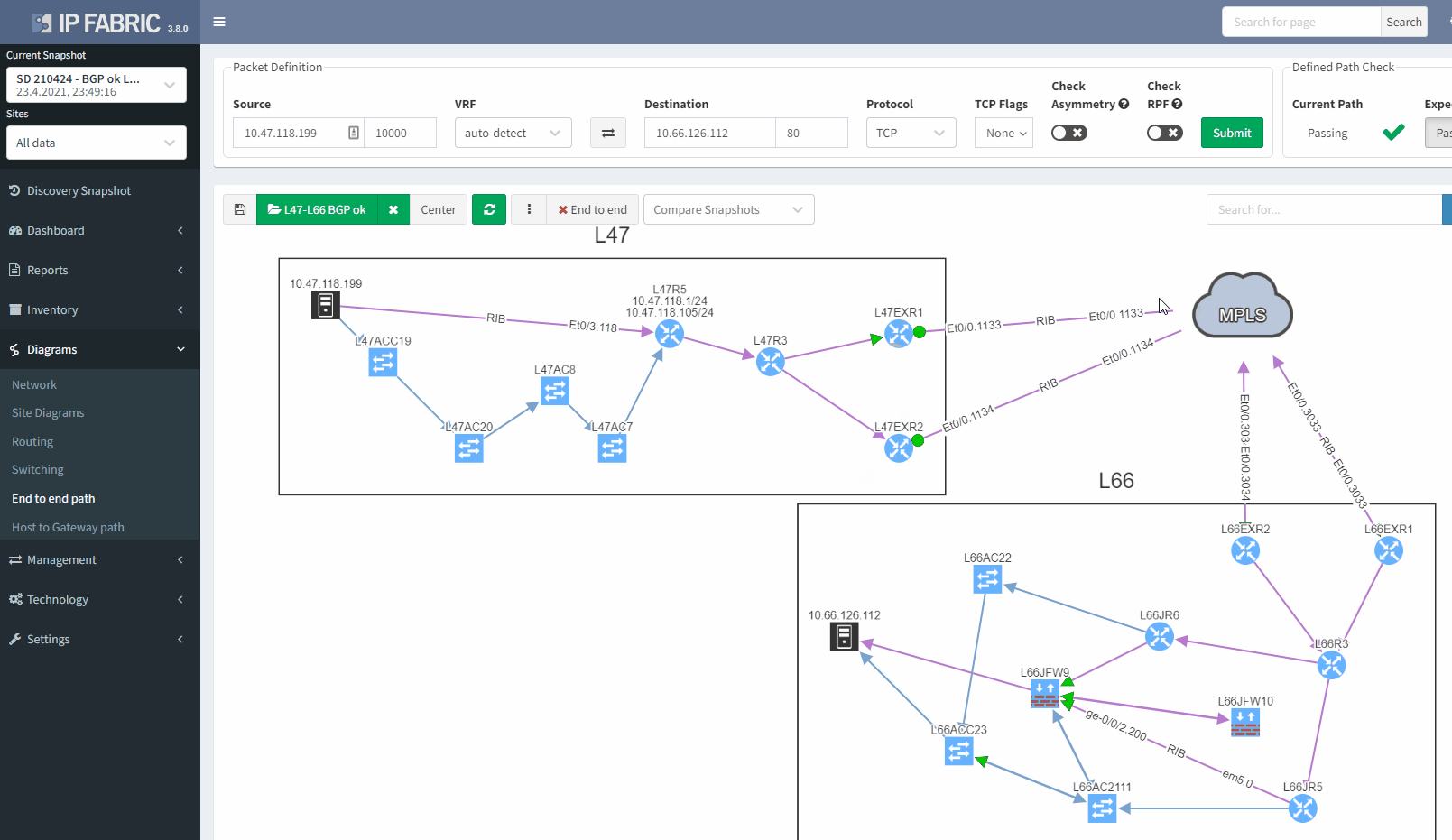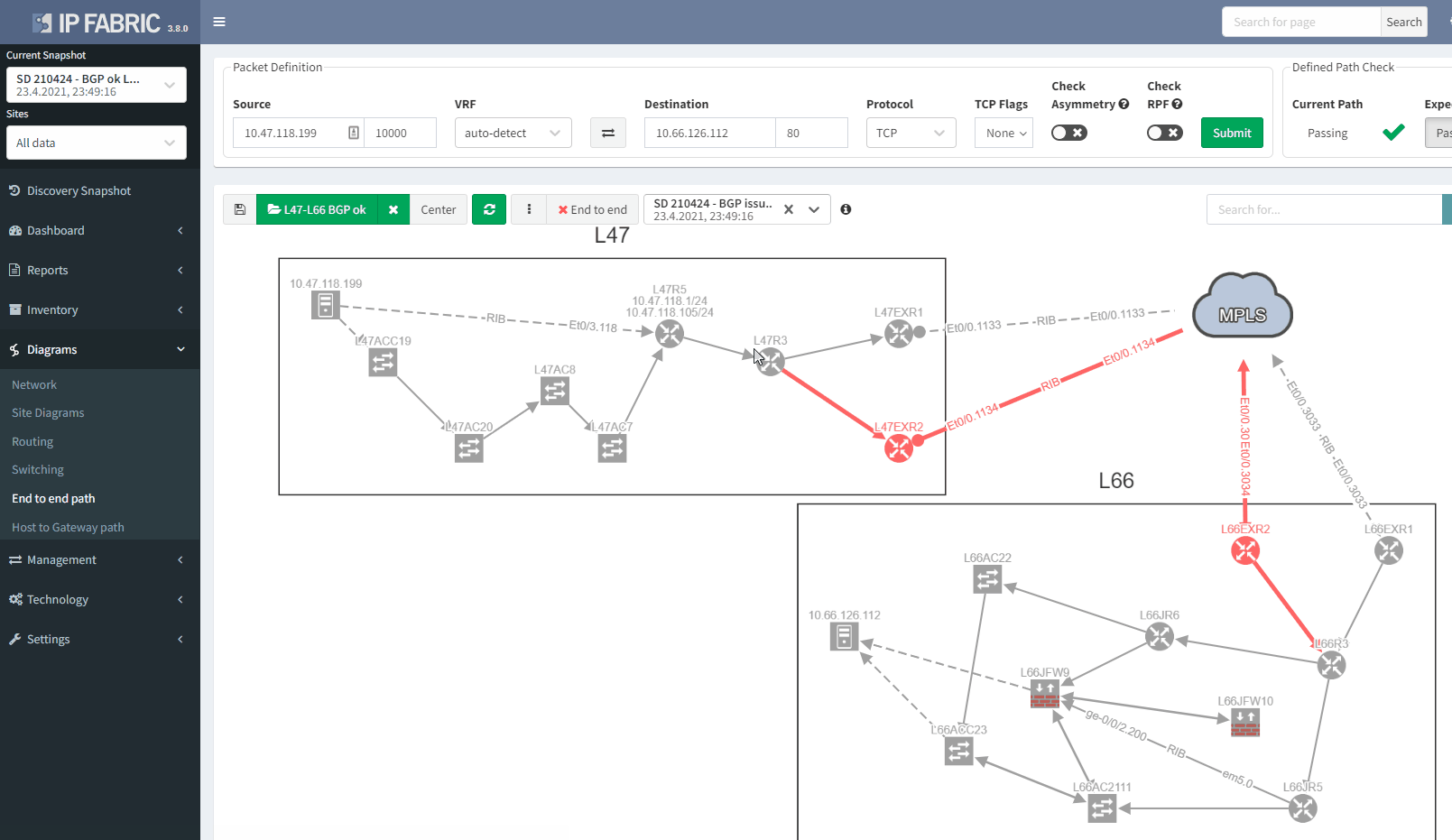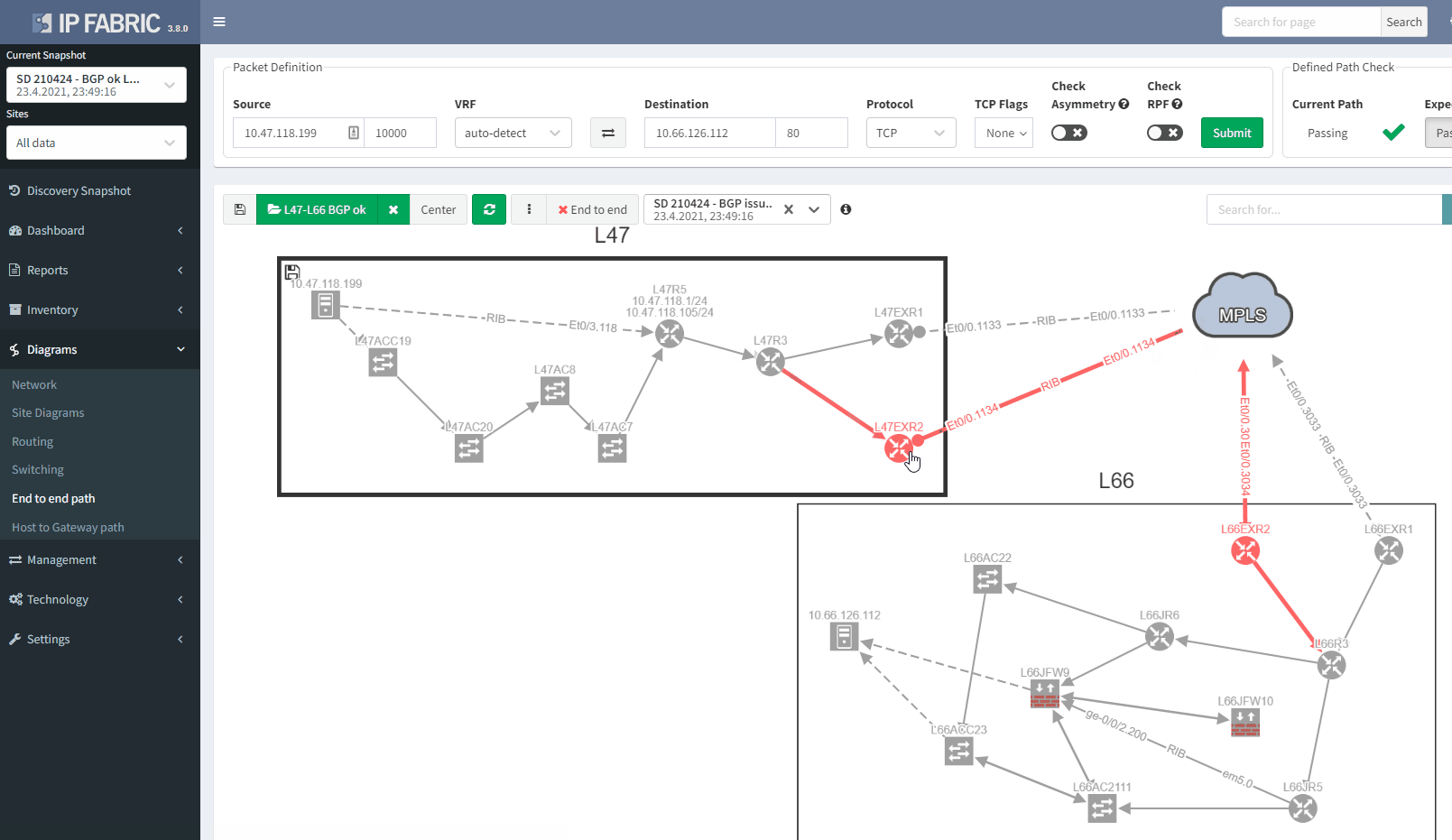
You can't ensure BGP resiliency if you do not look at the received prefixes. The main issue with this situation is the fact that your monitoring system will not be able to inform you of the loss of received prefixes. The last thing you want is to face a massive outage because of one link failure and your secondary link was not operational.
I have been in that exact situation previously, and let's just say I did not enjoy writing the postmortem explaining why we did not know our redundant path wasn't working. It's not a situation you want to be in...
If you would like to find out more about IP Fabric and how it can help improve your existing infrastructure by detecting issues you are not aware of, please contact us through www.ipfabric.io! You can also follow our company’s LinkedIn or Blog, where more content will be emerging.
There are many elements that contribute to the availability of services delivered across any network. Redundancy in the topology, coupled with resilience in the configuration are key. Routing protocols are used to manage that redundancy and failover to backup traffic paths should a failure occur in the active path. For this to work successfully, it is vital that the environment remains as stable as possible and is not subject to constant change. IP Fabric can help you by analyzing routing protocol stability and pinpointing issues.
As we know, the stability of BGP peering can cause performance problems with large networks. Events such as link failures can trigger sequences of updates along paths in the network - this can cause:
As an example of this, consider that the Internet routing table has reached such a size that it never actually fully converges. This is a symptom of the churn - the number of updates and withdrawals - caused by link events within and between ASs which of course occur around the clock!
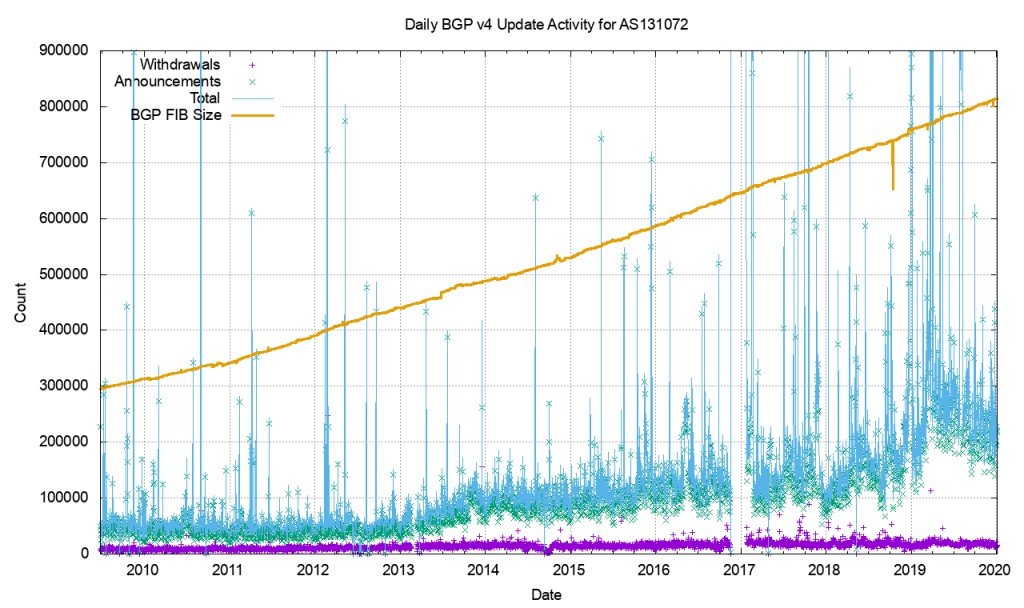
BGP is usually used in an enterprise to connect together networks that are managed by different organizations or different parts of the same organization. It follows then that once established, the connections should stay up and remain so. Fluctuations in that connectivity have the potential to have far-reaching consequences and so it pays to keep track of the stability of that peering.
But how do we measure that stability? In particular, we might address this by focussing on two particular elements. For each BGP peering relationship in the network we might look to answer two questions:
In order to check that manually, a network analyst might have to
Or you could spend the time to write the scripts and develop the tooling to automate the process so you can repeat the checks at regular intervals.
Alternatively, you could give the job to IP Fabric.
IP Fabric analyses configuration and operational state of the devices in the network records them in a vendor-agnostic form in its database, then runs 120+ standard validation checks and presents the results on the product dashboard. These checks include identifying BGP peering across platforms and vendors and checking the relationships for the length of the establishment of peering:

and for current state:

Clicking through the dashboard on peerings in an active state shows a table of the details for those peerings, and you have all the details to hand.
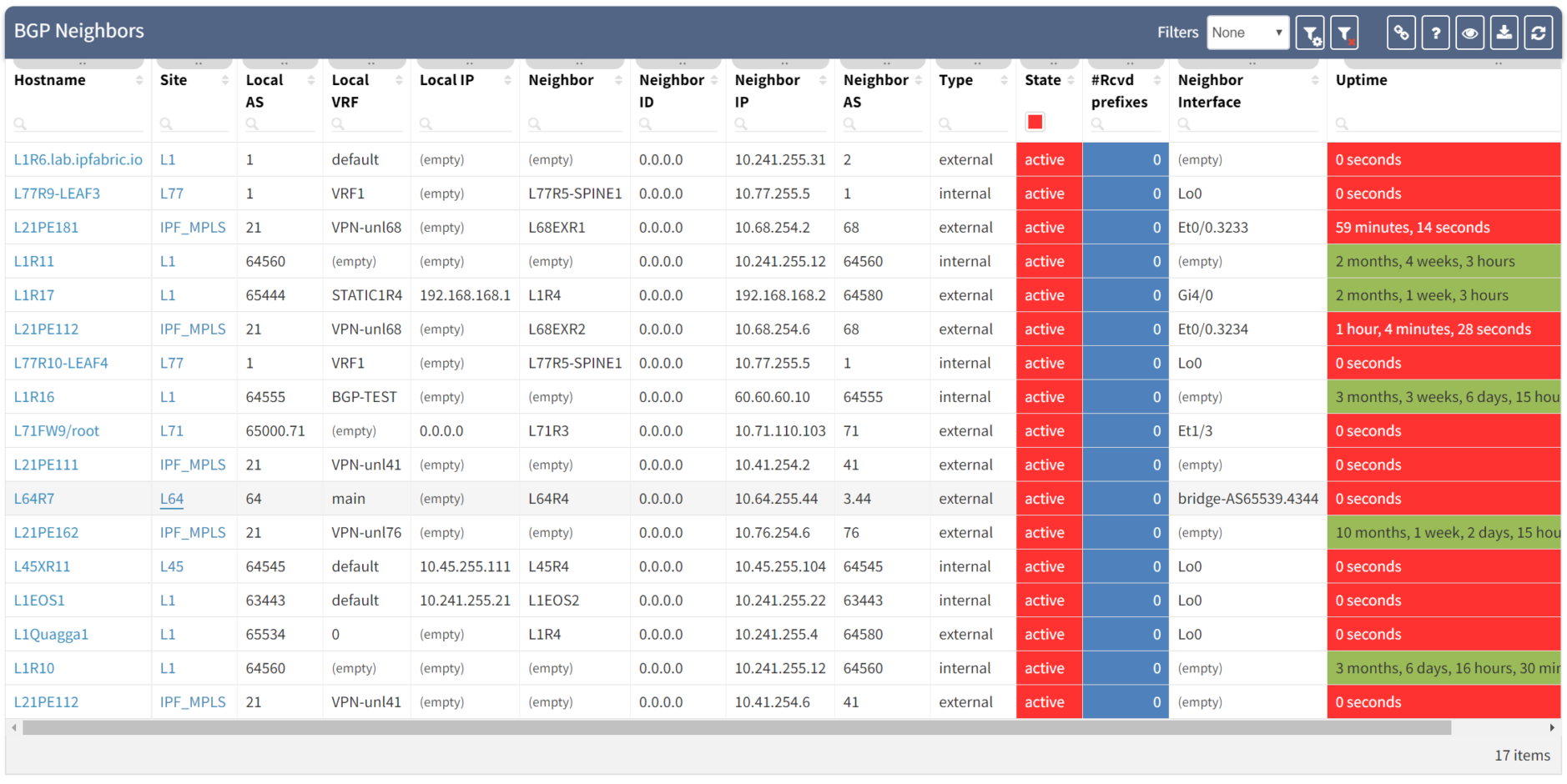
Taking a step further, click through the site location in the table to see the topology with the peering in question from the "live" documentation:
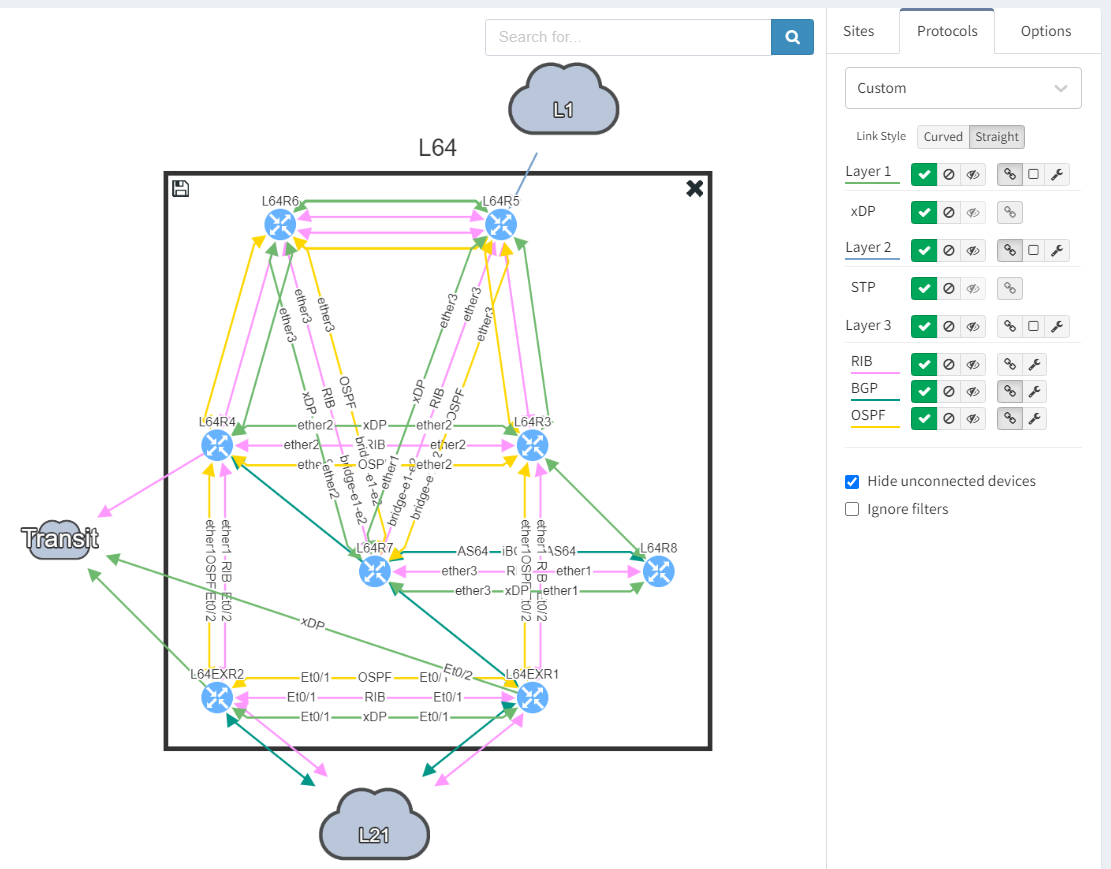
Next, we focus on BGP topology by disabling all other protocols and enable the BGP Compliance intent verification check.
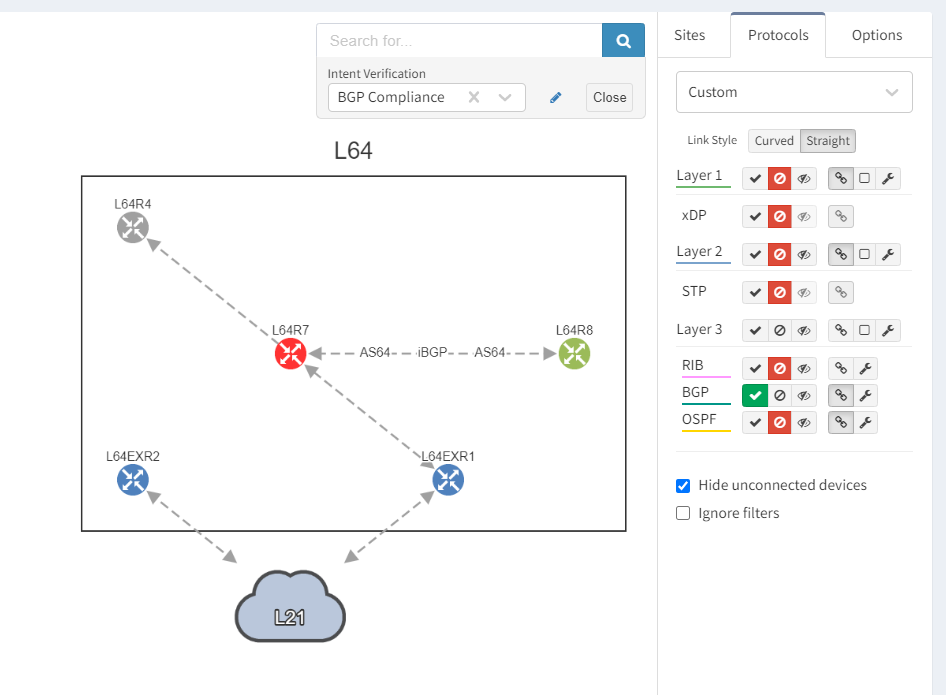
We can see that the platform has highlighted the problem with L64R7. IP Fabric presents information on the problematic peering with L64R4 when we select the router in question. The implication here is that L64R4 is not configured to peer with L64R7.
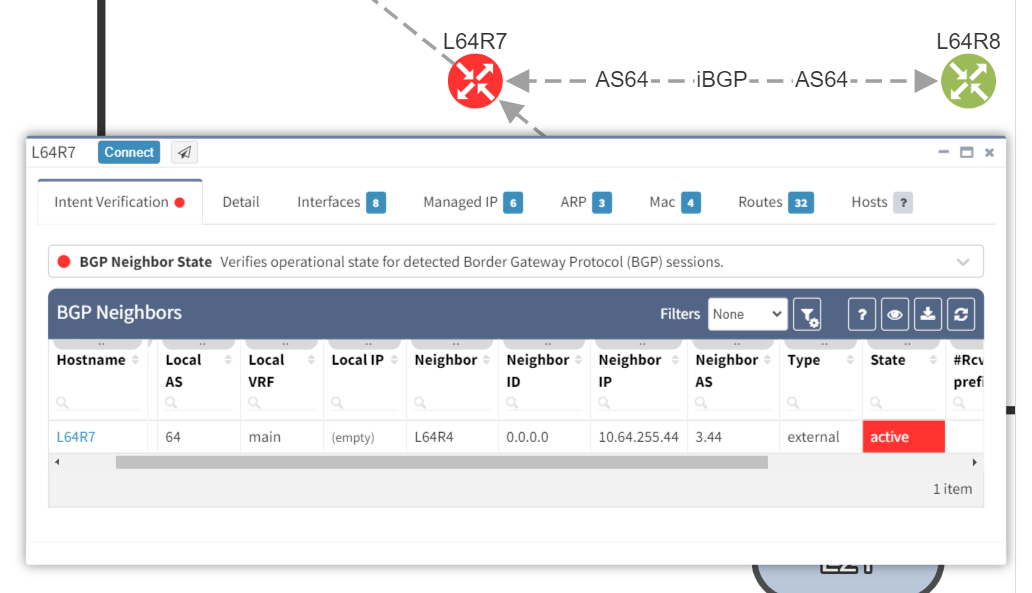
It is apparent that the peering appears to be configured in one direction and not the other from the arrows in the diagram. From the table, it looks like an IP address doesn't appear to be assigned to the peering. On inspecting the routers we can see that L64R7 looks fine:

but the peering is disabled on L64R4:
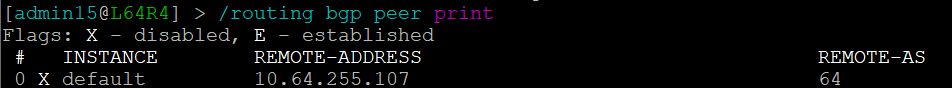
And so IP Fabric has allowed us to drill down and reach the conclusion far quicker than going through a process of having to extract the detail, analyze it and troubleshoot manually.
If you have found this article helpful, please follow our company’s LinkedIn or Blog, where more content will be emerging. If you would like to test our solution to see for yourself how IP Fabric can help you manage your network more effectively, please contact us through www.ipfabric.io.








